Explore Novel Techniques in Kv Cache Compression, Optimized Training Strategies, and Cost-Effective Attention Mechanisms for Enhanced Long-Context Language Modeling.
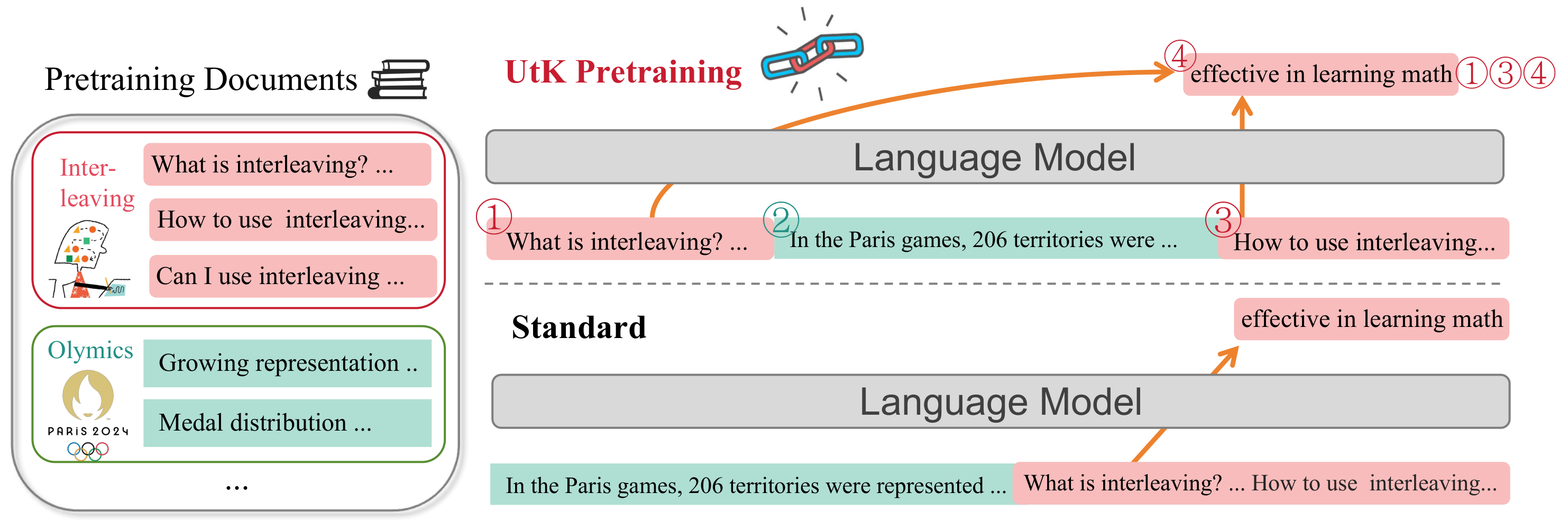
Explore New Techniques in Mutual Information Scaling, Normalization Strategies, and Training Data Selection for Enhanced Long-Context Language Modeling.
Explore the Newest Techniques in Hybrid Data Parallelism, Process-Supervised Learning, and Sliding Window Attention for Enhanced Long-Context Language Models.
Explore the Latest in Deep Learning for Handling Long Sequences, Including Novel Fine-Tuning, Hierarchical Byte-Level Models, and the Resurgence of CNNs.
Explore Novel Retrieval Methods And Efficient Processing Of 3M Tokens On Single GPU With RetroLM And InfiniteHiP. Learn About The Symbolic-Continuous Synthesis In LLMs.
Explore Novel Deep Learning Approaches to Extend Context Windows, Improve Memory Retention, and Optimize Computational Efficiency in LLMs.
Explore Novel Positional Encoding, Attention Mechanisms, And Tensor Manipulation Techniques For Improved Llm Performance And Context Retention.
Exploring Novel Architectures and Training Methodologies for Enhanced Long-Context Language Modeling, Including Transformer Performance Re-Evaluation and Synthetic Data Generation.
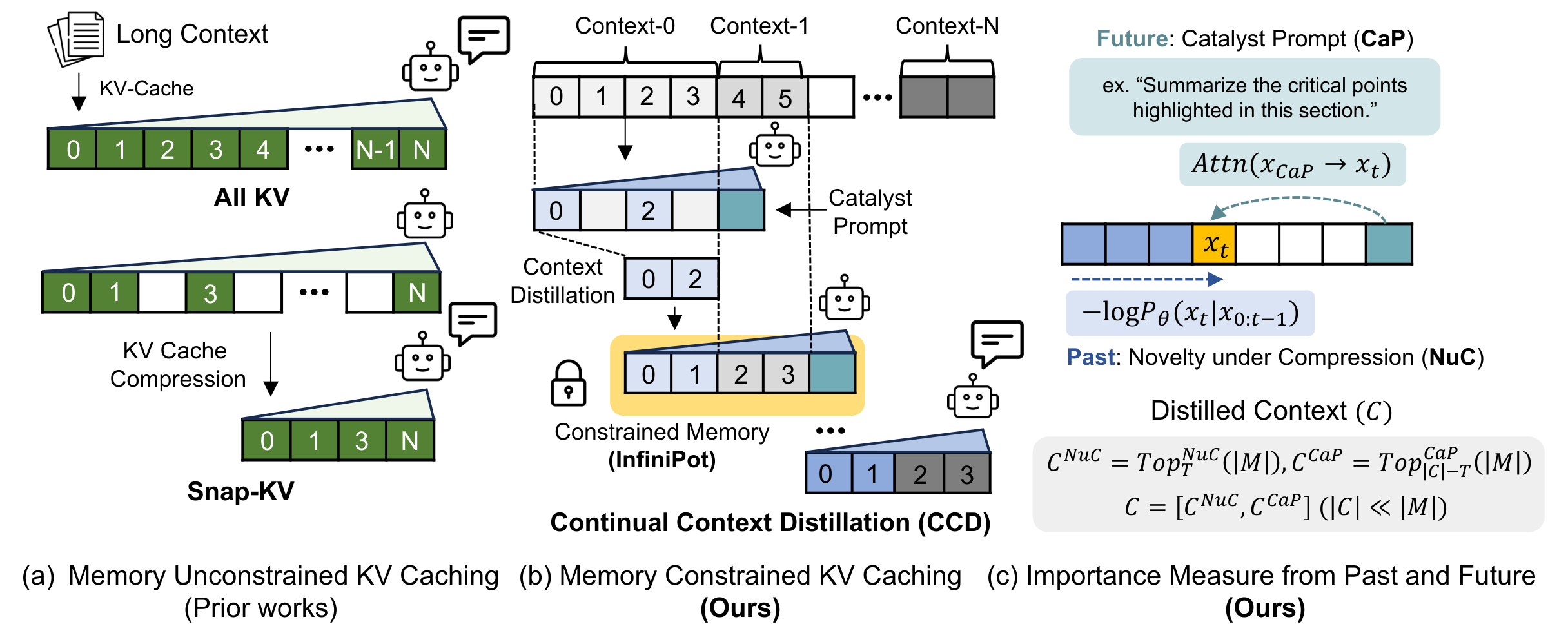
Explore Novel Attention Mechanisms, Hierarchical Memory, and Token Sparsity for Enhanced Language Models.
Explore Novel Architectures For Efficient Long-Context Language Modeling. TreeKV Optimizes KV Cache Compression, While AdaSkip Enables Adaptive Sublayer Skipping For Faster Inference.
Explore The Latest Technique to Train LLMs on 1M+ Token Sequences With Reduced Memory Footprint. Learn How Adjoint Sharding Enables Efficient Long Context Training.
Explore Novel Attention Mechanisms And Fine-Tuning Strategies For Enhanced Long-Context Language Modeling, Including Applications In Ehr Analysis.
Explore Novel Single-Stage Training With Harpe And Kv Cache-Centric Analysis With Scbench For Enhanced Long Context Language Modeling.
Exploring Novel Perceiver Architectures For Efficient Auto-Regressive Language Modeling With Long-Range Dependencies.
Explore a Novel Approach to Deep Learning Architecture Design Using Linear Input-Varying Systems for Improved Quality and Efficiency in Long Context Language Models.
Explore the Latest Breakthrough in Long-Context Language Modeling With Anchorattention, a Novel Attention Mechanism Designed to Improve Long-Context Capabilities and Accelerate Training.
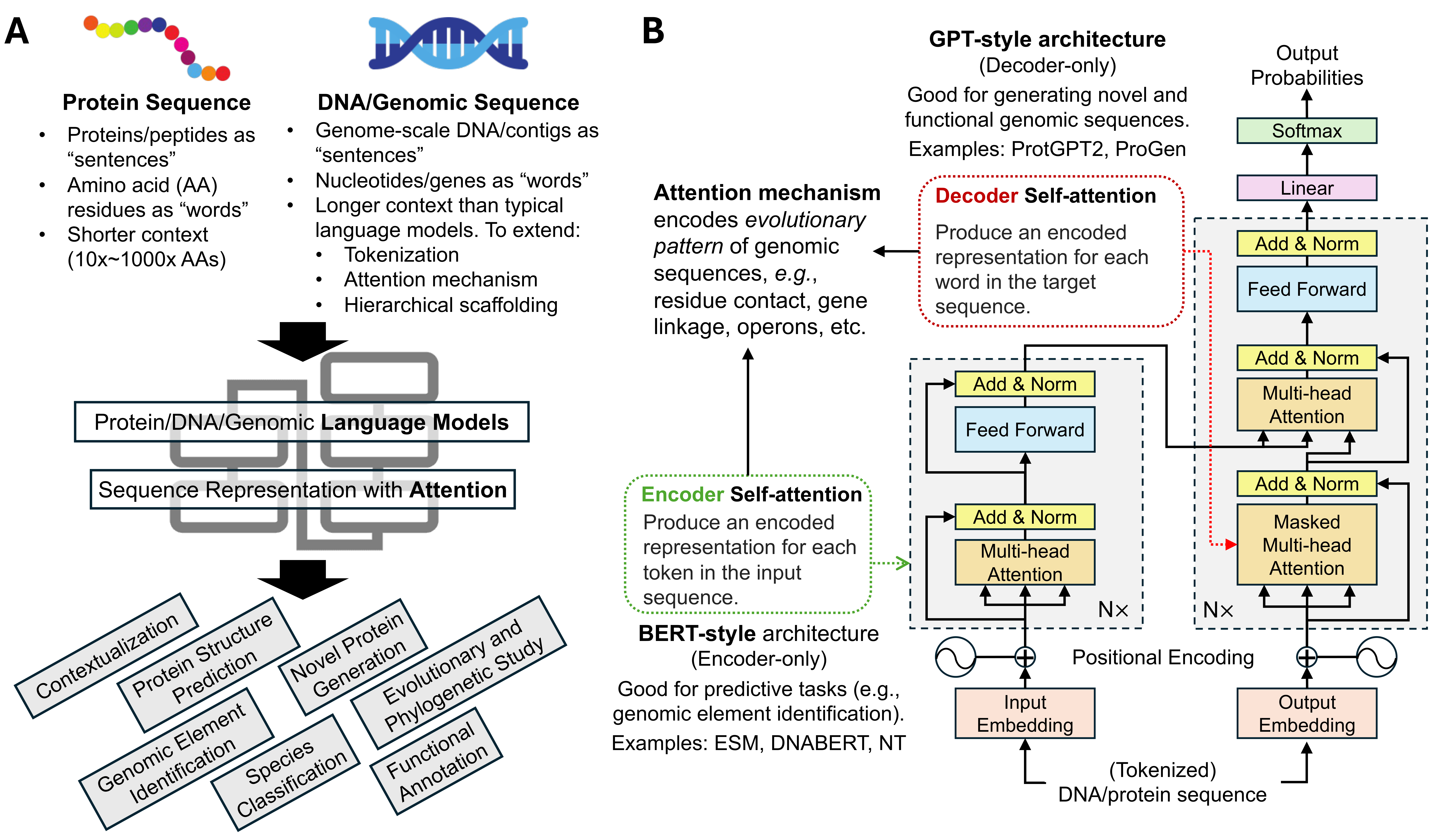
Explore Novel Attention Mechanisms, Theoretical Limits Of Rope, And Specialized Applications In Protein Analysis With Efficient Retrieval Strategies And Training Methods.
Explore Cutting-Edge Deep Learning Architectures Designed to Tackle the Challenges of Long Sequence Modeling, Including Recycled Attention, Bio-Xlstm, and Context Parallelism.
Explore the Latest in Tensorized Attention, Retrieval Heads, KV Cache Management, and Specialized Metrics for Enhanced Long-Context Language Processing.
Explore Novel Hybrid Architectures and Training Strategies for Efficient and Effective Long-Context Language Modeling, Including Preference Optimization, Selective Attention, and Context Compression.
Explore Novel Architectures For Million-Token Context: Duoattention'S Dual-Cache Approach And An In-Depth Analysis Of Long-Range Context Encoding In Transformer Models.
Explore State Collapse in RNNs and a Novel Metric, the Forgetting Curve, for Evaluating Long-Range Memory in Language Models.
Explore The Newest Techniques in Infinite Context Processing, Hybrid Architectures, and Optimized Training for LLMs.
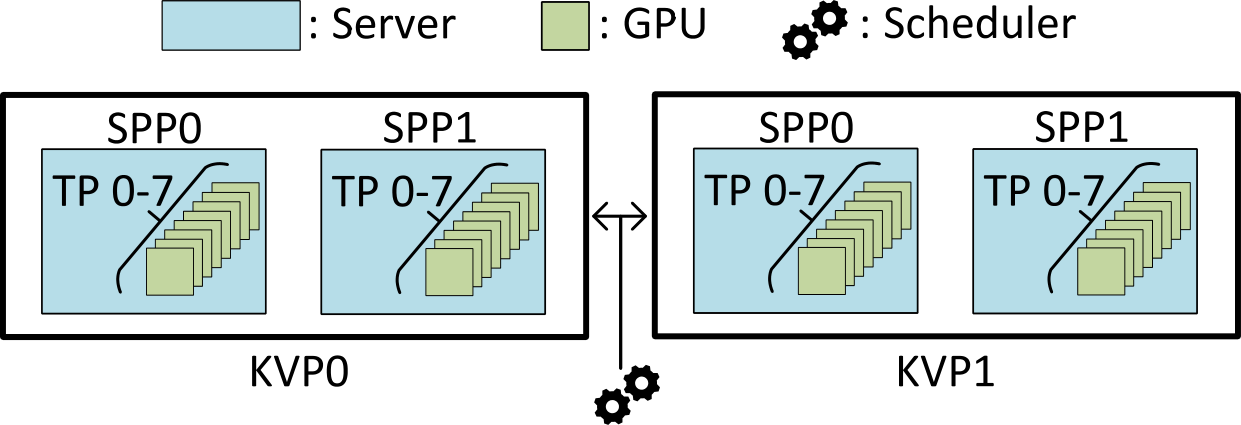
Explore Novel Parallelization Strategies And Input Reduction Techniques For Efficient Llm Inference With Extremely Long Contexts.
Exploring The Latest Techniques For Enhancing Context Length, Accelerating Inference, And Breaking Free From Traditional Transformer Limitations In Language Models.
Explore The Newest Architectures And Evaluation Frameworks Designed To Push The Boundaries Of Long-Context Language Modeling.