Delving into the Evolving Landscape of Long-Context Language Modeling
Dear Elman,
This newsletter delves into the latest advancements in deep learning architectures designed to tackle the challenges of long-context language modeling. As you know, extending the context window of LLMs is crucial for enabling more sophisticated and contextually aware language processing.
We'll explore novel approaches to enhance context length, including leveraging the phenomenon of "grokking" for improved copying abilities, introducing new benchmarks for evaluating long-context reasoning, and exploring innovative architectures that break free from the limitations of traditional Transformer models. Additionally, we'll examine techniques for accelerating inference in long-context LLMs, paving the way for more efficient and scalable deployment of these powerful models.
Let's dive into the details!
Unveiling the Link Between "Grokking" and Context Copying in Language Models
Language Models "Grok" to Copy by Ang Lv, Ruobing Xie, Xingwu Sun, Zhanhui Kang, Rui Yan https://arxiv.org/abs/2409.09281
 Caption: This image shows the relationship between the learning rate of a language model and its ability to copy text from context. The graphs demonstrate that higher learning rates lead to faster "grokked copying," where the model's copying accuracy suddenly improves after a period of stagnation, similar to the phenomenon of grokking. The y-axis represents the copying accuracy and loss, while the x-axis represents the number of tokens processed during training.
Caption: This image shows the relationship between the learning rate of a language model and its ability to copy text from context. The graphs demonstrate that higher learning rates lead to faster "grokked copying," where the model's copying accuracy suddenly improves after a period of stagnation, similar to the phenomenon of grokking. The y-axis represents the copying accuracy and loss, while the x-axis represents the number of tokens processed during training.
This paper explores a fascinating parallel between how language models develop the ability to copy text from context and the intriguing phenomenon of "grokking" observed in machine learning. Grokking refers to a sudden and often unexpected improvement in a model's performance on a test set long after its performance on the training set has plateaued.
The authors meticulously trained 12-layer Llama models on a 40-billion-token subset of the RedPajama dataset, tracking their context copying accuracy alongside the traditional training loss. Their findings revealed that while the training loss stabilized relatively quickly, the models' ability to accurately copy text from the preceding context lagged significantly. Then, mirroring the pattern observed in grokking, the copying accuracy suddenly shot up.
Further solidifying this connection, the researchers discovered that the speed of this "grokked copying" was independent of the number of tokens the model was trained on. This characteristic aligns with a hallmark of grokking itself. They also found that the learning rate significantly impacted the speed of grokked copying: higher learning rates led to a faster acquisition of copying ability. This suggests that the dynamics of optimization play a crucial role in both grokking and the development of copying abilities.
Interestingly, the researchers observed that the "induction heads" — specialized attention heads responsible for copying — formed in a shallower-to-deeper layer progression during training. This pattern mirrors the development of circuits in deeper layers observed during grokking, further strengthening the link between the two phenomena.
This intriguing connection between grokking and context copying opens up new avenues for improving language models. The authors demonstrated that leveraging techniques known to enhance grokking, such as regularization, could either accelerate the acquisition of copying abilities or improve the final copying accuracy. This connection could lead to more efficient research by allowing researchers to study grokking on smaller, synthetic datasets and then apply those insights to improve the in-context learning capabilities of larger language models.
Beyond Haystacks: Introducing Michelangelo, a Novel Benchmark for Long-Context Reasoning
Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries by Kiran Vodrahalli et al. https://arxiv.org/abs/2409.12640
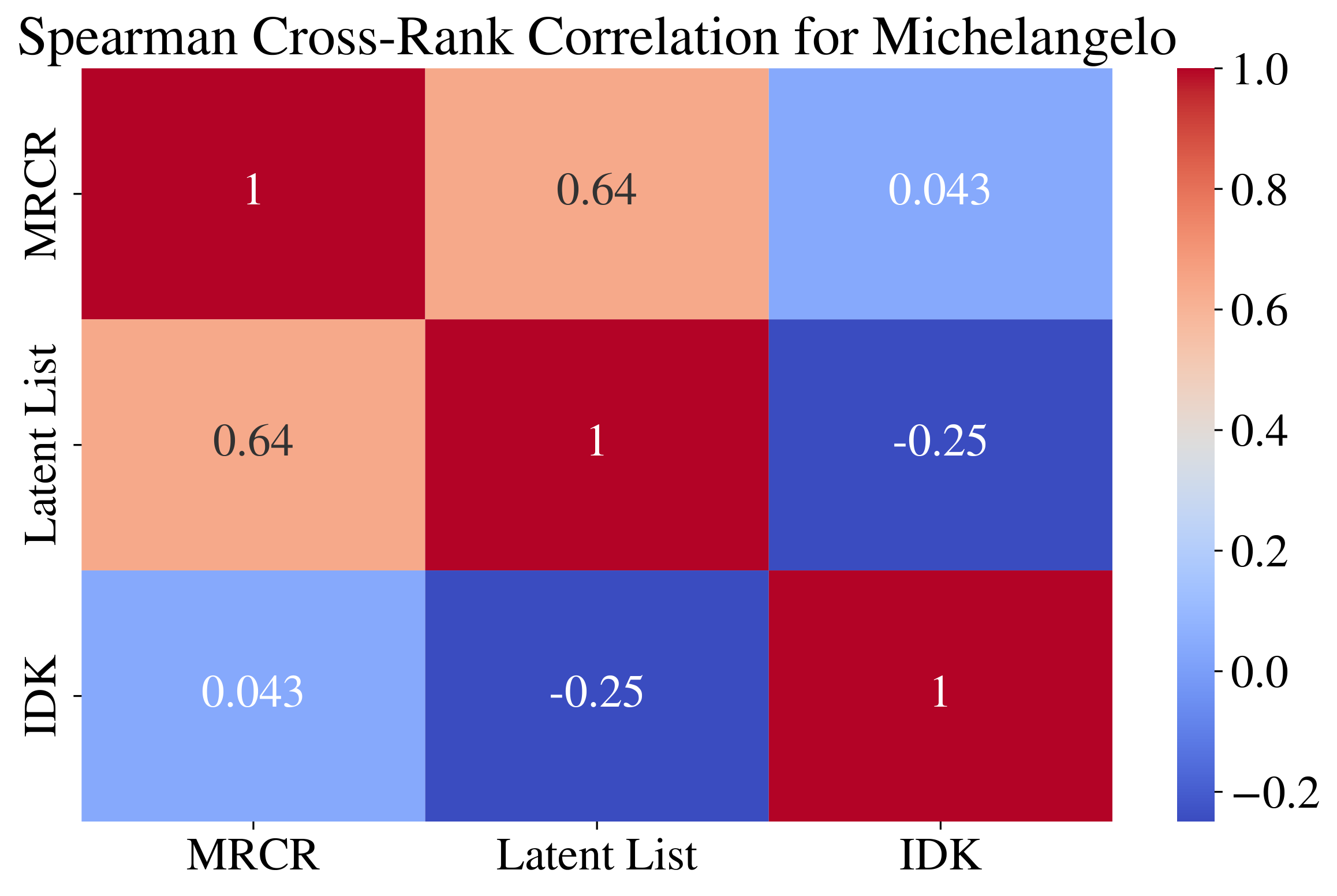 Caption: This figure shows the Spearman cross-rank correlation between the three tasks in the Michelangelo benchmark: Latent List, Multi-Round Co-reference Resolution (MRCR), and IDK. The strong correlation between Latent List and MRCR suggests that MRCR, with its simplicity and high signal, could be a suitable replacement for the commonly used Needle-in-a-Haystack evaluation.
Caption: This figure shows the Spearman cross-rank correlation between the three tasks in the Michelangelo benchmark: Latent List, Multi-Round Co-reference Resolution (MRCR), and IDK. The strong correlation between Latent List and MRCR suggests that MRCR, with its simplicity and high signal, could be a suitable replacement for the commonly used Needle-in-a-Haystack evaluation.
The recent surge in LLMs with extended context lengths, reaching up to 1 million tokens, has highlighted a critical gap in our ability to reliably evaluate their true long-context reasoning capabilities. Existing benchmarks often focus on retrieval tasks, akin to finding needles in haystacks, which don't necessarily assess a model's capacity to synthesize information from the full context.
This paper introduces Michelangelo, a new benchmark designed to address this gap. It's built on the Latent Structure Queries (LSQ) framework, which emphasizes evaluating a model's ability to "chisel away" irrelevant information and reveal the underlying structure within a large context. Michelangelo comprises three minimal, synthetic, and unleaked tasks: Latent List, Multi-Round Co-reference Resolution (MRCR), and IDK. These tasks are designed to be arbitrarily extendable in context length and complexity, offering a more nuanced and challenging evaluation of long-context reasoning.
The researchers evaluated ten state-of-the-art LLMs, including Gemini, GPT, and Claude models, on Michelangelo. The results revealed a significant initial performance drop across all models on these tasks, even at relatively short context lengths (32K). However, Gemini models demonstrated non-degrading performance from 128K to 1M context, suggesting a potential advantage in handling very large contexts. Interestingly, different model families excelled in different tasks: Gemini on MRCR, GPT on Latent List, and Claude-3.5 Sonnet on IDK. This underscores the diversity of long-context understanding captured by Michelangelo.
The authors argue that MRCR, due to its robustness, simplicity, and high signal, could serve as a suitable replacement for the popular Needle-in-a-Haystack evaluation. They emphasize that Michelangelo's focus on synthesis and reasoning over long contexts provides a more comprehensive assessment of LLMs' capabilities beyond mere retrieval. This work highlights the need for more sophisticated evaluation methods to accurately gauge the progress and limitations of LLMs in handling increasingly large amounts of information.
Deep Learning and Language Models Revolutionize Microbiome Research
Recent advances in deep learning and language models for studying the microbiome by Binghao Yan, Yunbi Nam, Lingyao Li, Rebecca A. Deek, Hongzhe Li, Siyuan Ma https://arxiv.org/abs/2409.10579
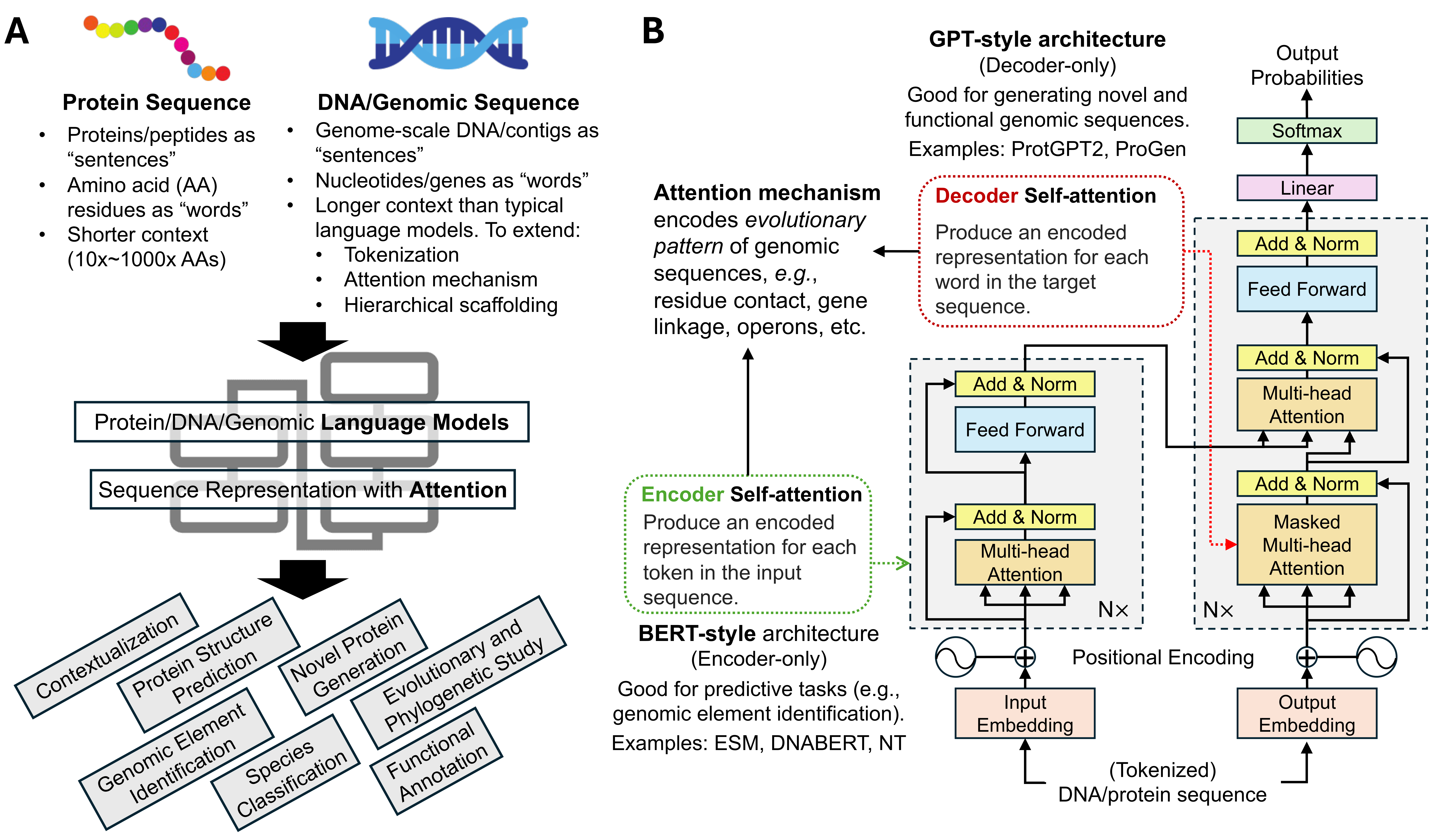 Caption: Protein and DNA/genomic language models are transforming microbiome research. These models utilize attention mechanisms to capture evolutionary patterns within sequences, enabling them to predict protein structures, generate novel proteins, identify genomic elements, and classify microbial species. This figure illustrates the architectures of these models, highlighting their ability to process and interpret the "language of life."
Caption: Protein and DNA/genomic language models are transforming microbiome research. These models utilize attention mechanisms to capture evolutionary patterns within sequences, enabling them to predict protein structures, generate novel proteins, identify genomic elements, and classify microbial species. This figure illustrates the architectures of these models, highlighting their ability to process and interpret the "language of life."
Deep learning and language models, inspired by breakthroughs in natural language processing, are transforming the study of microbiomes and metagenomics. These models leverage the inherent "language of life" within microbial protein and genomic sequences to extract meaningful insights from complex microbial communities.
Protein language models (PLMs) are trained on vast datasets of microbial protein sequences, enabling them to generate novel, functionally viable proteins and predict protein structures and functions directly from amino acid sequences. For example, ProtGPT2 and ProGen, trained on millions of protein sequences, demonstrate the ability to generate novel proteins with properties comparable to natural proteins. Similarly, ESMFold, leveraging billions of parameters, predicts protein 3D structures with remarkable accuracy, even for metagenomic sequences.
DNA/genomic language models tackle the challenges posed by the scale and complexity of microbial genomes. Models like DNABERT and NT are trained on multi-species genomes, learning to predict genomic elements, differentiate microbial species, and provide contextualized representations of genes within their genomic neighborhoods. This contextualization is crucial for understanding gene regulation, horizontal gene transfer, and the organization of functional gene clusters.
The integration of deep learning and language models extends beyond individual proteins and genomes. Researchers are now applying these techniques to study virome-host interactions. Models like ViraLM leverage pre-trained genome foundation models to identify novel viral contigs in metagenomic data. Additionally, models like evoMIL, trained on curated virus-host interaction databases, predict potential virus-host associations at the species level based on viral sequence data. These advancements are crucial for understanding viral diversity, function, and their impact on host health.
Long-Context LLMs Still Struggle to Generalize Beyond Training Lengths
A Controlled Study on Long Context Extension and Generalization in LLMs by Yi Lu et al. https://arxiv.org/abs/2409.12181
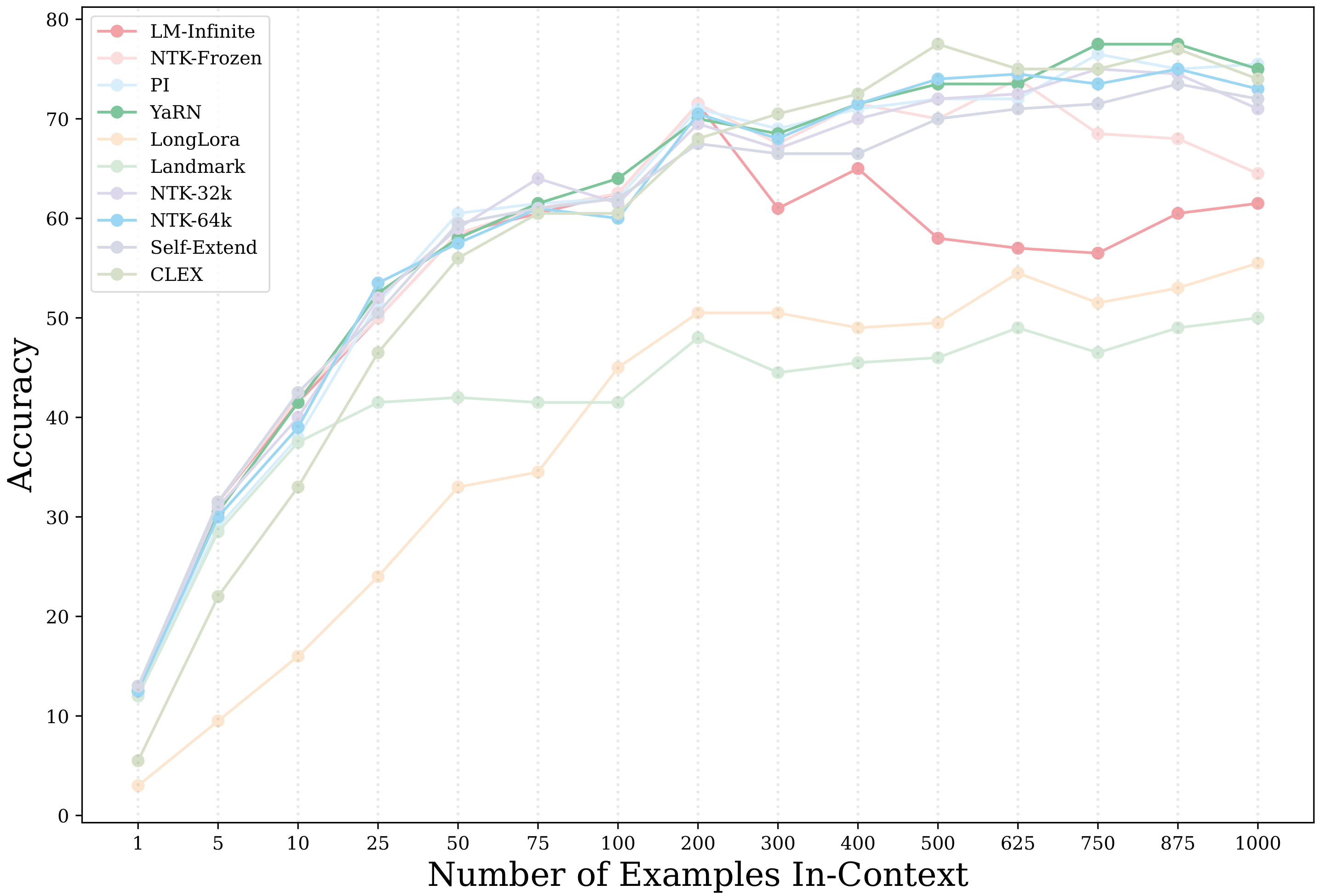 Caption: This graph depicts the accuracy of different long-context language models (LLMs) as the number of in-context examples increases. The results demonstrate that fine-tuned exact attention methods, particularly NTK-32k and YaRN, consistently outperform approximate attention and frozen methods on in-context learning tasks.
Caption: This graph depicts the accuracy of different long-context language models (LLMs) as the number of in-context examples increases. The results demonstrate that fine-tuned exact attention methods, particularly NTK-32k and YaRN, consistently outperform approximate attention and frozen methods on in-context learning tasks.
This paper presents a controlled study on long-context extension and generalization in Large Language Models (LLMs). The authors highlight the challenges in comparing different context extension methods due to variations in base models, training data, and evaluation metrics. To address this, they propose a standardized protocol that controls for these factors, enabling a more reliable comparison of different approaches.
The study focuses on extending the context window of a LLaMa2-7B model from 4k to 32k tokens, using a consistent dataset and training recipe. They evaluate various exact attention methods (Position Interpolation, NTK-ROPE, YaRN, CLEX) and approximate attention methods (LongLoRA, Landmark Attention, LM-Infinite, Self-Extend) along with frozen models. The evaluation encompasses intrinsic metrics like perplexity and retrieval accuracy, as well as extrinsic tasks from LongBench, RULER, and TREC News.
The results demonstrate that fine-tuned exact attention methods, particularly NTK-32K and YaRN, consistently outperform approximate attention and frozen methods. This suggests that while approximate methods offer computational benefits, they compromise accuracy, particularly in tasks requiring extensive context utilization. Interestingly, despite exhibiting good perplexity scores, LM-Infinite struggles to generalize beyond its 4k context window, highlighting the importance of evaluating downstream task performance at different lengths.
The study also finds a strong correlation between perplexity and downstream task performance for most exact attention methods, challenging the notion that perplexity is insufficient for evaluating long-context models. However, the authors acknowledge limitations, including the use of a single base model size and training context length. They emphasize the need for further research with larger models and longer training contexts to validate the generalizability of their findings.
RetrievalAttention: A New Approach to Accelerating Long-Context LLM Inference
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval by Di Liu et al. https://arxiv.org/abs/2409.10516
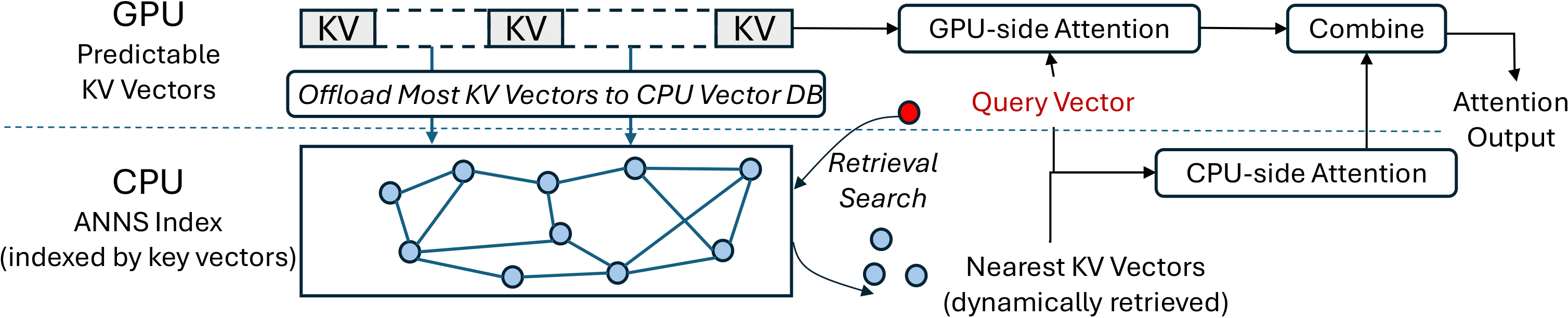 Caption: The diagram illustrates the architecture of RetrievalAttention, a novel approach to accelerate long-context LLM inference. It leverages an ANNS index on CPU memory to dynamically retrieve the most relevant KV vectors during generation, significantly reducing GPU memory requirements and inference latency. This allows for efficient attention computation on much longer contexts while maintaining model accuracy.
Caption: The diagram illustrates the architecture of RetrievalAttention, a novel approach to accelerate long-context LLM inference. It leverages an ANNS index on CPU memory to dynamically retrieve the most relevant KV vectors during generation, significantly reducing GPU memory requirements and inference latency. This allows for efficient attention computation on much longer contexts while maintaining model accuracy.
Transformer-based large language models (LLMs) are revolutionizing various domains, but their quadratic time complexity for attention operations poses a significant challenge for scaling to longer contexts. This is due to the extremely high inference latency and GPU memory consumption required for caching key-value (KV) vectors. Existing methods for addressing this challenge, such as KV caching, static or heuristic token selection, and offloading KV vectors to CPU memory, often lead to either significant performance degradation or substantial memory requirements.
This paper introduces RetrievalAttention, a novel training-free approach that leverages the dynamic sparse property of attention to accelerate attention computation. RetrievalAttention builds approximate nearest neighbor search (ANNS) indexes upon KV vectors in CPU memory and retrieves the most relevant ones via vector search during generation. To address the out-of-distribution (OOD) problem between query vectors and key vectors, RetrievalAttention employs an attention-aware vector search algorithm that adapts to queries and only accesses a small subset (1-3%) of data. This approach effectively reduces the time complexity of attention computation while maintaining model accuracy.
RetrievalAttention significantly reduces the inference cost of long-context LLMs with much lower GPU memory requirements while maintaining the model accuracy. Experimental results demonstrate that RetrievalAttention achieves up to 4.9x and 1.98x decoding-latency reduction compared to existing retrieval methods based on exact KNN and traditional ANNS indexing, respectively, while maintaining the same accuracy as full attention. Notably, RetrievalAttention is the first solution that enables running 8B-level models on a single 4090 GPU (24GB) with acceptable latency and almost no accuracy degradation for a context length of 128k tokens.
The success of RetrievalAttention highlights the potential of leveraging dynamic sparse attention and efficient vector search techniques for accelerating long-context LLM inference. Future work could explore more sophisticated static patterns for identifying important KV vectors, as well as advanced vector quantization techniques for further reducing CPU memory usage.
Adaptive Large Language Models Break Free from Rigid Architectures
Adaptive Large Language Models By Layerwise Attention Shortcuts by Prateek Verma, Mert Pilanci https://arxiv.org/abs/2409.10870
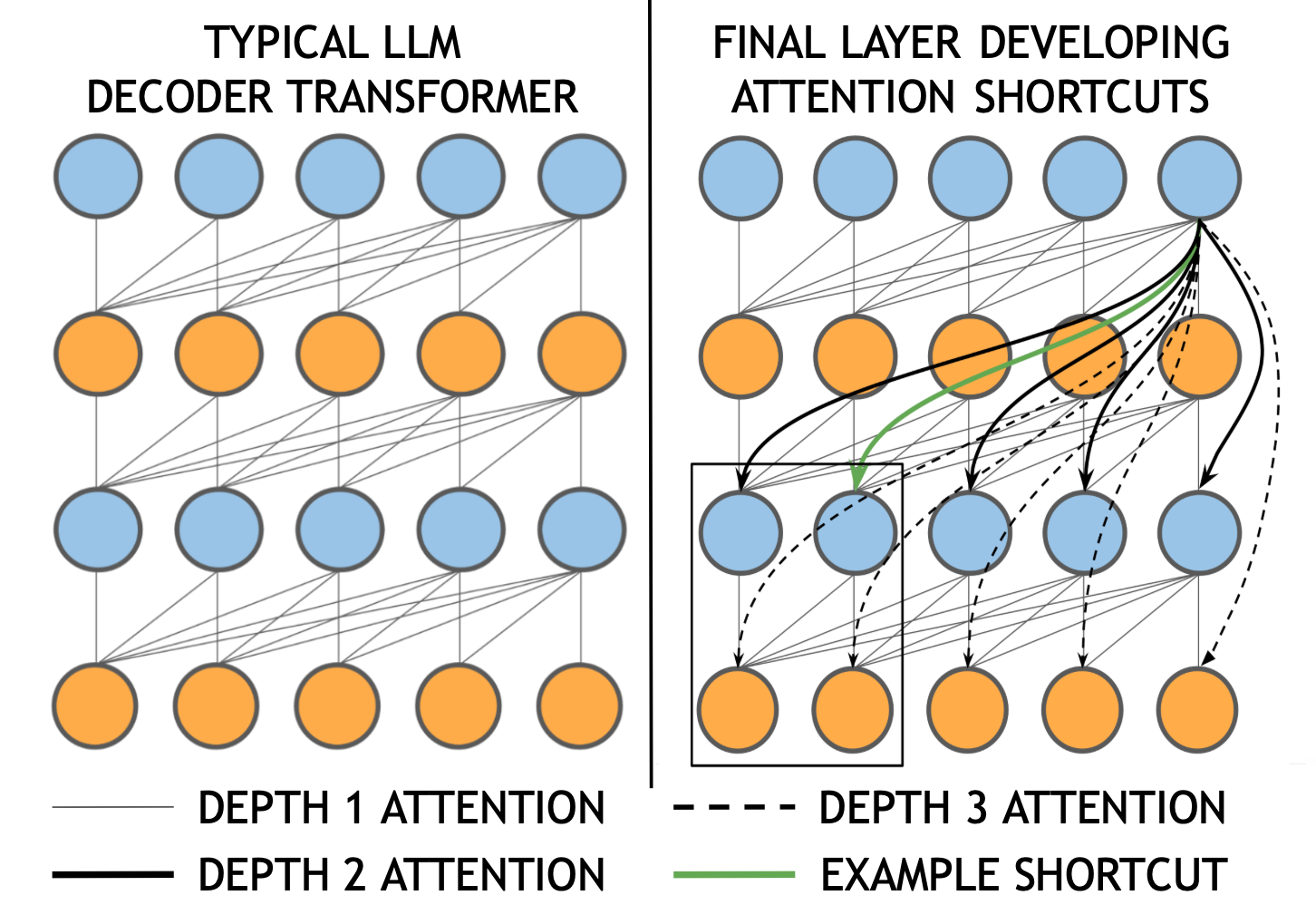 Caption: The image illustrates the concept of "attention shortcuts" in an adaptive large language model (LLM). The left side depicts a typical LLM decoder transformer with sequential attention layers. The right side shows how the final layer in the adaptive architecture can directly access information from any previous layer (highlighted by the green line), bypassing unnecessary computations and improving efficiency.
Caption: The image illustrates the concept of "attention shortcuts" in an adaptive large language model (LLM). The left side depicts a typical LLM decoder transformer with sequential attention layers. The right side shows how the final layer in the adaptive architecture can directly access information from any previous layer (highlighted by the green line), bypassing unnecessary computations and improving efficiency.
Transformer architectures have become ubiquitous in AI, but their rigid, sequential processing of information limits their efficiency and adaptability. This paper challenges this status quo by introducing adaptive computations that allow the final layer of an LLM-like model to directly access and utilize information from any intermediate layer. This is achieved through an attention mechanism, creating computational attention shortcuts that bypass unnecessary computations and make the model's depth and context-aware.
The researchers tested their approach on four diverse datasets spanning speech (LibriSpeech), symbolic music (MAESTRO), and natural language (text-8 and Wiki-103). The results are compelling: the adaptive architecture consistently outperforms the baseline Transformer model in terms of negative log-likelihood scores, a key metric for language model pre-training. Notably, the most significant speed-up was observed with the MAESTRO dataset, highlighting the architecture's ability to efficiently capture structured information.
A key insight from the paper is the potential for bypassing entire layers of computation for certain input tokens. The authors draw on recent work showing that the output of multiple Transformer layers can sometimes be approximated by a single MLP layer. By allowing the model to learn these shortcuts during pre-training, computational resources are optimized, and the model can focus on more complex dependencies.
Further analysis of the attention maps reveals that the model learns to adaptively leverage intermediate layer representations based on the input. For instance, when processing early tokens in a sequence with limited context, the model relies heavily on deeper layers. As more context becomes available, it dynamically shifts its attention to shallower layers, demonstrating a context-aware adaptation of computation. This work opens up exciting avenues for developing more efficient and adaptable LLM architectures that move beyond the limitations of simple layer stacking.
Conclusion
This newsletter has explored several cutting-edge advancements in the field of long-context language modeling. From drawing intriguing parallels between "grokking" and context copying to introducing novel benchmarks like Michelangelo that move beyond simple retrieval tasks, researchers are continuously pushing the boundaries of what LLMs can achieve with extended contexts.
The development of techniques like RetrievalAttention, which leverages dynamic sparse attention and efficient vector search, demonstrates a clear focus on accelerating inference and making long-context LLMs more practical for real-world applications. Moreover, exploring adaptive architectures that introduce computational shortcuts within the traditional Transformer framework shows promise in overcoming the limitations of rigid, sequential processing.
As research in this area progresses, we can anticipate even more innovative approaches to emerge, further enhancing the capabilities of LLMs and expanding their applicability across diverse domains.