Deep Dive into Long-Context Language Modeling: New Architectures and Evaluation Frameworks
Dear Elman,
This newsletter delves into the latest advancements in long-context language modeling, a field rapidly gaining prominence in natural language processing (NLP). As you know, the ability of large language models (LLMs) to effectively process and understand extended sequences of text is crucial for tackling complex tasks such as document summarization, multi-round dialogue systems, and intricate code generation.
This week, we explore three cutting-edge research papers that introduce novel architectures and evaluation frameworks designed to push the boundaries of long-context language modeling. From innovative data augmentation strategies to insightful task categorization frameworks, these papers offer a glimpse into the future of LLMs.
Untying the Knots for Efficient Long-Context Pre-Training
Untie the Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models by Junfeng Tian, Da Zheng, Yang Cheng, Rui Wang, Colin Zhang, Debing Zhang https://arxiv.org/abs/2409.04774
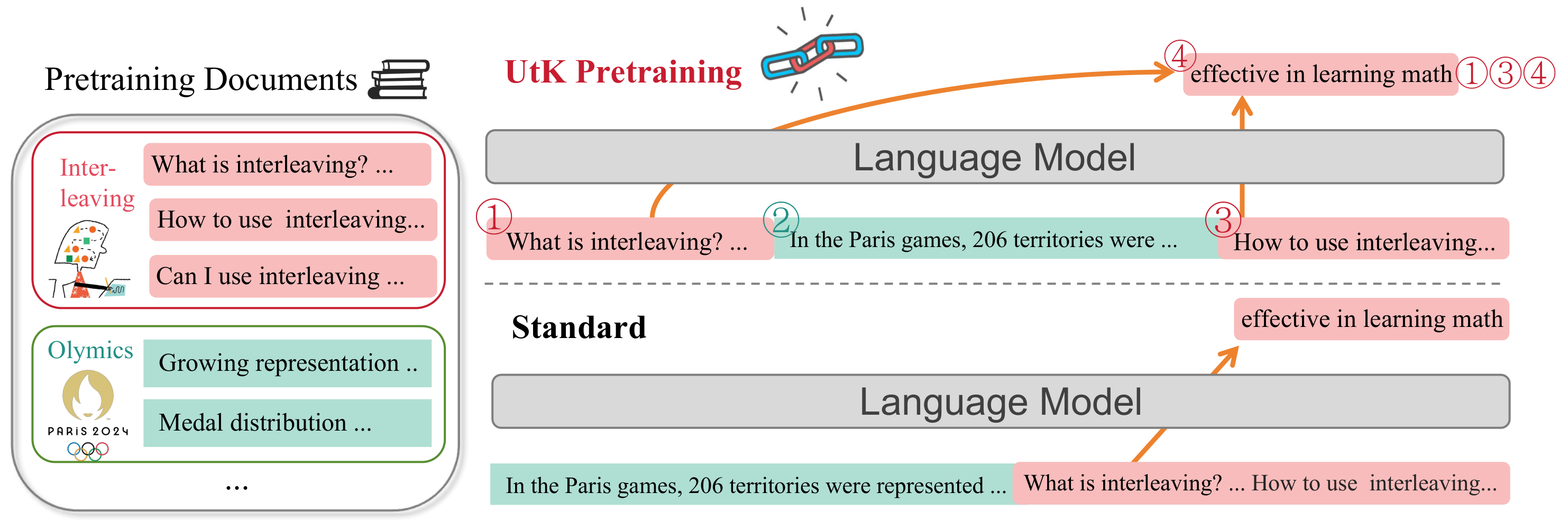 Caption: This image illustrates the "Untie the Knots" (UtK) data augmentation strategy for long-context language modeling. UtK involves chunking, shuffling, and reconstructing input documents to train models on identifying relevant information across longer sequences. The diagram highlights how UtK helps the model learn relationships between distant segments within a document, ultimately improving its ability to answer questions and perform tasks requiring long-context understanding.
Caption: This image illustrates the "Untie the Knots" (UtK) data augmentation strategy for long-context language modeling. UtK involves chunking, shuffling, and reconstructing input documents to train models on identifying relevant information across longer sequences. The diagram highlights how UtK helps the model learn relationships between distant segments within a document, ultimately improving its ability to answer questions and perform tasks requiring long-context understanding.
This paper introduces Untie the Knots (UtK), a novel data augmentation strategy aimed at enhancing the long-context capabilities of LLMs without requiring modifications to the existing data mixture. This approach addresses several key challenges in long-context language modeling, including the scarcity of high-quality long-context data, potential performance degradation on short-context tasks, and reduced training efficiency associated with attention mechanisms.
The UtK strategy operates through a three-step process: chunking, shuffling, and reconstructing input documents. Initially, documents are divided into smaller chunks. These chunks are then shuffled, creating a complex, interwoven structure of text segments. The model is then tasked with "untying these knots" by identifying and reconstructing the original order of these shuffled segments, thereby learning to attend to relevant information across extended sequences.
To further enhance long-context learning, the researchers introduce a backtracing task. This task prompts the model to explicitly locate all corresponding segments within the shuffled sequence and arrange them in their correct order. This encourages the model to not only identify relevant segments but also to understand their precise contextual relationships within the larger document.
The researchers conducted continue pre-training of language models with 7B and 72B parameters on a dataset comprising 20 billion tokens, employing the UtK strategy. Their findings reveal that UtK surpasses other long-context strategies in performance. Notably, on the RULER benchmark, UtK achieved a 15.0% performance gain. Similarly, on the LV-Eval benchmark for 128K context tasks, UtK demonstrated a 17.2% improvement. These enhancements represent over 90% of the performance achieved on 32K contexts, highlighting the effectiveness of UtK in scaling to longer sequences.
The success of UtK can be largely attributed to its ability to guide the model's attention towards longer, interconnected chunks of information while simultaneously preserving its capacity to accurately reconstruct the original context. This focused approach proves to be more effective than simply increasing the training sequence length or relying on techniques like position interpolation.
The research team behind UtK plans to open-source two well-trained models, Qwen2-UtK-7B-base 128K and Qwen2-UtK-72B-base 128K. This open-source release aims to foster further exploration and development within the domain of long-context language modeling.
Deciphering Long-Context Tasks: A New Evaluation Framework
Retrieval Or Holistic Understanding? Dolce: Differentiate Our Long Context Evaluation Tasks by Zi Yang https://arxiv.org/abs/2409.06338
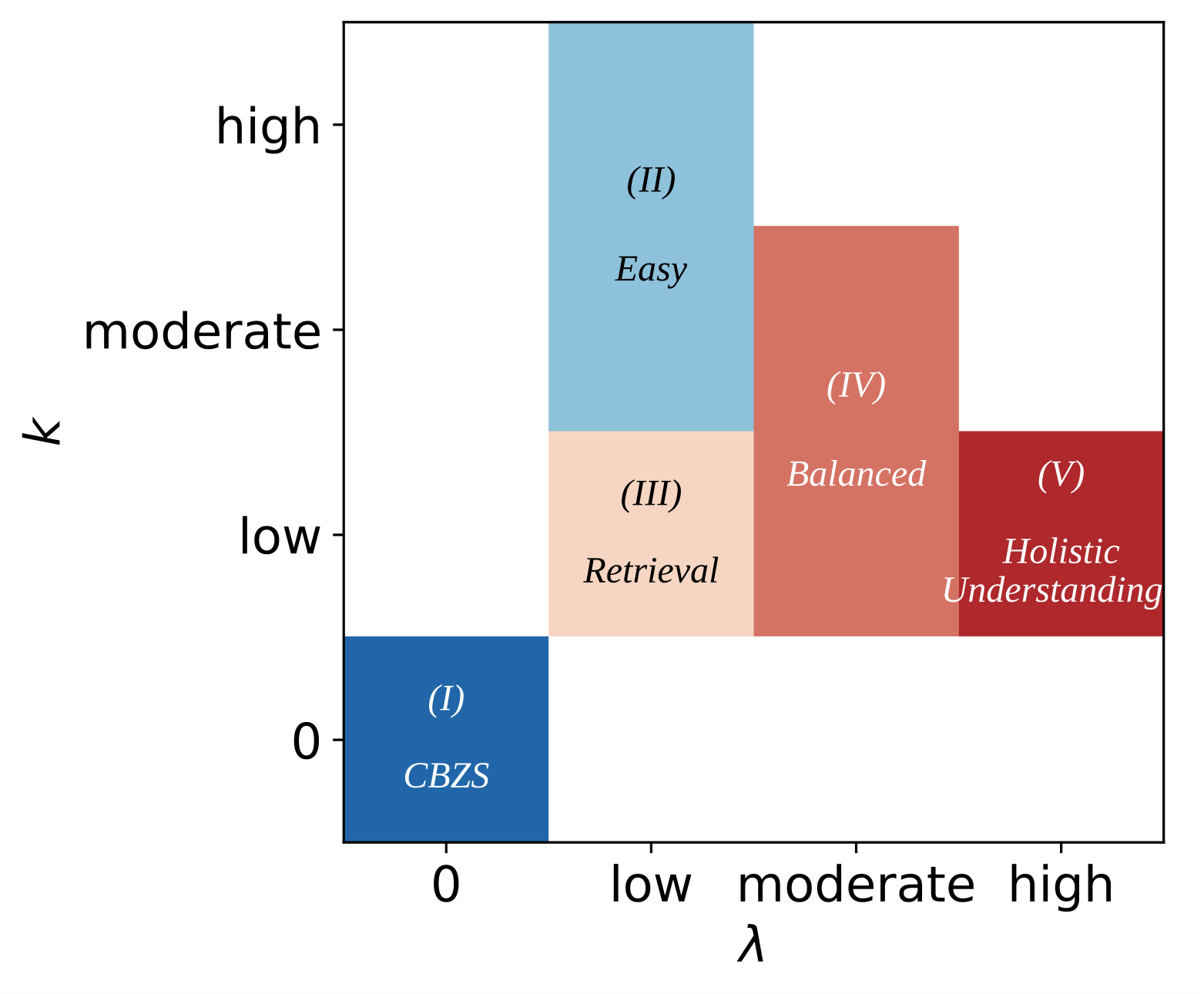 Caption: The DOLCE (Differentiate Our Long Context Evaluation Tasks) framework automatically categorizes long context tasks and quantifies their difficulty using two parameters: λ (complexity) and k (redundancy). This image shows the λ-k plane mapped to five predefined focus categories: (I) CBZS, (II) Easy, (III) Retrieval, (IV) Balanced, and (V) Holistic Understanding.
Caption: The DOLCE (Differentiate Our Long Context Evaluation Tasks) framework automatically categorizes long context tasks and quantifies their difficulty using two parameters: λ (complexity) and k (redundancy). This image shows the λ-k plane mapped to five predefined focus categories: (I) CBZS, (II) Easy, (III) Retrieval, (IV) Balanced, and (V) Holistic Understanding.
This paper delves into a critical aspect of long-context language modeling: understanding the nature of the tasks themselves. The author posits that long-context understanding can be broadly categorized into two fundamental capabilities: retrieval and holistic understanding.
Retrieval involves pinpointing specific information within a large context, much like a search engine. Holistic understanding, on the other hand, necessitates processing the entire context to grasp the nuanced relationships and meaning between different parts, often considering the order of information. Recognizing this distinction is crucial for designing effective LLMs, as different architectures may be better suited for one type of task over the other.
To address this challenge, the paper introduces DOLCE (Differentiate Our Long Context Evaluation Tasks), a novel framework designed to automatically categorize long-context tasks and quantify their difficulty. DOLCE leverages two key parameters:
- λ (complexity): representing the minimum length of text span containing sufficient information to solve the task.
- k (redundancy): representing the number of such informative spans present within the context.
DOLCE maps each region of the λ-k plane to one of five predefined focus categories:
- (I) CBZS: Corresponds to zero-shot scenarios where the model has not been explicitly trained on the task.
- (II) Easy: Represents tasks with low complexity and high redundancy.
- (III) Retrieval: Encompasses tasks requiring primarily information retrieval.
- (IV) Balanced: Includes tasks that exhibit a balance between retrieval and holistic understanding.
- (V) Holistic Understanding: Represents tasks demanding significant holistic understanding of the context.
The DOLCE framework employs a probing model to observe and analyze the responses generated by an LLM when presented with sampled short contexts extracted from the full context. This analysis helps in estimating the probability of the LLM successfully solving the task using only these sampled spans.
To determine the λ and k values for each task, DOLCE utilizes a mixture model. This model comprises two components: a non-parametric background noise component representing irrelevant information and a parametric/non-parametric hybrid oracle component that models the LLM's ability to utilize relevant information. The probability functions associated with both correct-or-wrong (COW) and partial-point-in-grading (PIG) scenarios are derived and parameterized by λ and k.
Applying DOLCE to 44 diverse tasks sourced from three prominent benchmark suites and utilizing two different LLMs (Gemini 1.5 Flash and PaLM 2-S), the author discovered that a significant portion of these tasks necessitate holistic understanding. Specifically, 0% to 67% of the COW problems and 0% to 29% of the PIG problems were categorized as retrieval-focused. In contrast, 0% to 89% of the COW problems and 8% to 90% of the PIG problems fell under the holistic understanding category. This finding underscores the importance of developing LLMs equipped to effectively process and comprehend entire contexts.
Furthermore, the paper investigates the influence of various modeling decisions on parameter estimation within the DOLCE framework. Different sampling strategies, unit granularities, probing models, and binarization thresholds are explored. The author observes that "take" strategies, which involve shifting the observation window by a fixed number of units, generally yield favorable results. Additionally, the ranking of λ and k remains relatively consistent across different unit granularities.
Bridging Efficiency and Performance: A Novel Architecture for Long-Context LLMs
E2LLM: Encoder Elongated Large Language Models for Long-Context Understanding and Reasoning by Zihan Liao, Jun Wang, Hang Yu, Lingxiao Wei, Jianguo Li, Jun Wang, Wei Zhang https://arxiv.org/abs/2409.06679
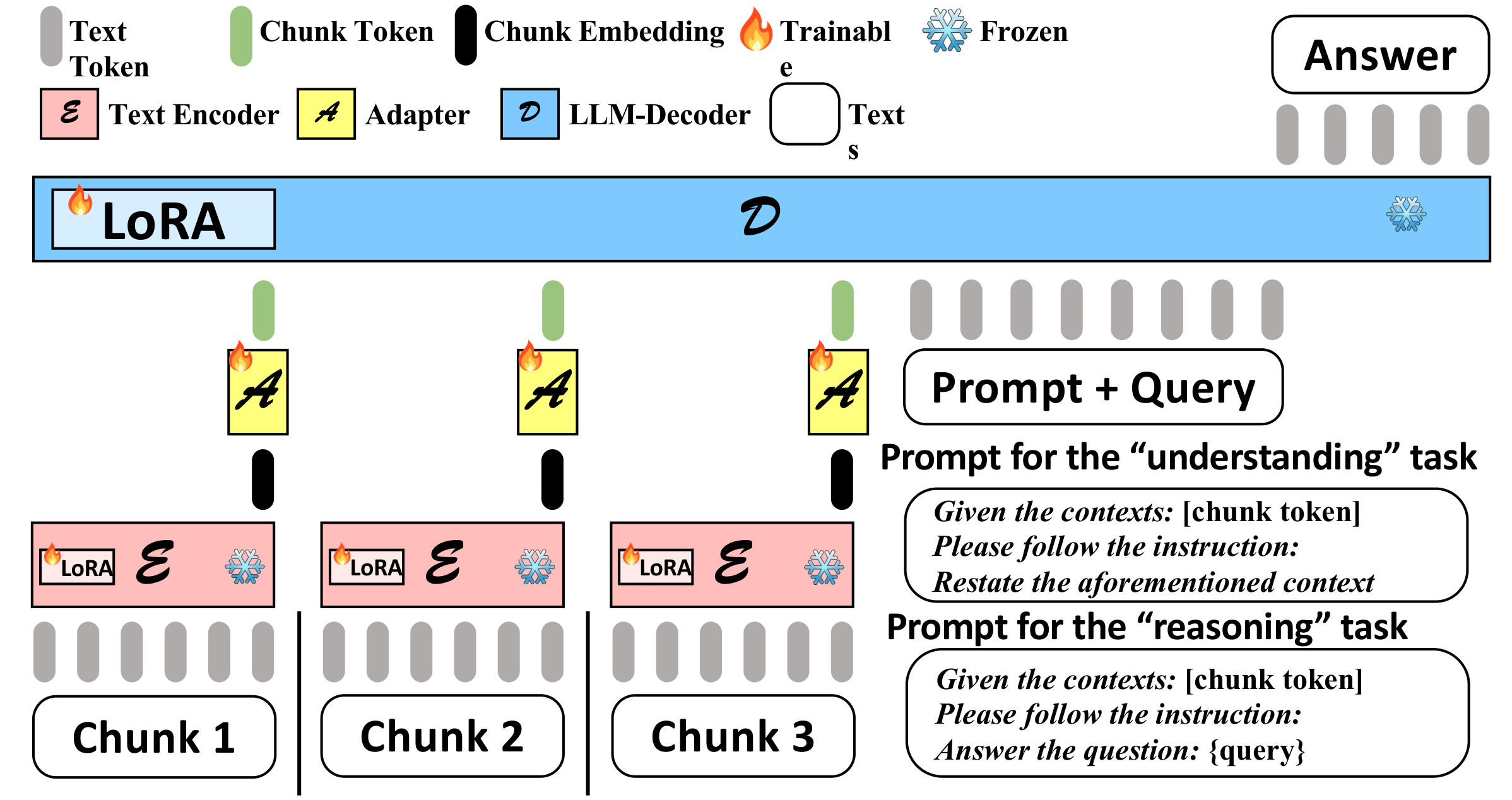 Caption: The image illustrates the E2LLM framework, which enhances LLMs' ability to handle long contexts by compressing them into smaller chunks using a pretrained text encoder and an adapter. It highlights two key training objectives: "understanding" for context reconstruction and "reasoning" for answering questions based on the compressed information.
Caption: The image illustrates the E2LLM framework, which enhances LLMs' ability to handle long contexts by compressing them into smaller chunks using a pretrained text encoder and an adapter. It highlights two key training objectives: "understanding" for context reconstruction and "reasoning" for answering questions based on the compressed information.
This paper tackles the challenge of enhancing LLMs' ability to handle long contexts while addressing the often-encountered "impossible triangle" of trade-offs between performance, efficiency, and compatibility with pretrained models. The authors introduce E2LLM (Encoder Elongated Large Language Models), a novel framework designed to navigate these trade-offs effectively.
E2LLM leverages the strengths of both pretrained text encoders and LLM decoders. It employs a multi-step process:
- Chunking: The long context is divided into smaller, more manageable chunks.
- Encoding: Each chunk is fed into a pretrained text encoder, which compresses the information into a dense embedding vector.
- Alignment: An adapter is used to align these embeddings with the input embedding space of a decoder-only LLM. This allows the LLM to understand and utilize the compressed information from the encoder.
- Dual Training Objectives: To ensure effective alignment and comprehension, E2LLM employs two training objectives:
- "Understanding": This objective focuses on reconstructing the encoder's input from the LLM's output, ensuring that the LLM effectively captures the essence of the compressed context.
- "Reasoning": This objective involves training the LLM to answer questions based on the compressed context, encouraging it to utilize the compressed information for downstream tasks.
Experimental results showcase E2LLM's superior performance in long-context scenarios. In document question answering tasks, for instance, E2LLM consistently outperforms other methods, achieving a notable 16.39% improvement compared to models lacking the "understanding" objective.
Beyond its performance gains, E2LLM also demonstrates remarkable efficiency. It boasts the lowest runtime and memory usage among the compared methods, particularly when dealing with extended sequences. This efficiency stems from two key factors:
- Parallel Processing: E2LLM processes chunks in parallel, significantly reducing the overall processing time.
- High Compression Ratio: The use of a pretrained text encoder allows for a high compression ratio, reducing the computational burden on the LLM decoder.
Several factors contribute to E2LLM's success. Firstly, its reliance on pretrained models minimizes the need for extensive additional training, making it a more practical solution. Secondly, the "understanding" objective ensures that the LLM develops a robust understanding of the compressed context. Lastly, E2LLM's parallel processing capabilities and high compression ratio contribute significantly to its exceptional efficiency.
Conclusion
This newsletter highlighted three impactful papers that advance the field of long-context language modeling. UtK presents a practical and effective data augmentation strategy for improving long-context performance during pre-training. DOLCE introduces a much-needed framework for categorizing and quantifying the difficulty of long-context tasks, providing valuable insights for LLM design and evaluation. E2LLM offers a novel architecture that effectively balances performance, efficiency, and compatibility with pretrained models, paving the way for more powerful and practical long-context LLMs.
These advancements collectively contribute to a deeper understanding of long-context language modeling and provide a foundation for developing increasingly sophisticated and capable LLMs in the future.