## General Overview
This collection of preprints explores diverse methodological advancements and applications across statistics, machine learning, and applied fields. Several papers focus on innovative approaches to modeling complex data structures and dynamics. Ragni, Masci, and Paganoni (2024) ([Ragni et al., 2024](https://arxiv.org/abs/2411.13370)) introduce a novel methodology for analyzing higher education dropout patterns using ***multilevel functional decomposition of recurrent events*** within a counting process framework. Their approach combines ***Cox-based recurrent event models*** and ***functional data analysis*** to disentangle program- and school-level effects on dropout risk. Similarly, Visalli et al. (2024) ([Visalli et al., 2024](https://arxiv.org/abs/2411.13203)) propose a new computational framework, ***Predictive evidence Accumulation Models (PAM)***, integrating predictive processes into established Evidence Accumulation Models (EAMs). This framework combines Bayesian perceptual inference models with EAMs to model decision-making under uncertainty. Elsewhere, Haines (2024) ([Haines, 2024](https://arxiv.org/abs/2411.13356)) investigates the use of ***spherical *t*-designs*** as optimal designs for ***spherical harmonic regression*** in three dimensions.
Another recurring theme is the development of robust and efficient methods for uncertainty quantification and prediction. Principato et al. (2024) ([Principato et al., 2024](https://arxiv.org/abs/2411.13479)) explore the integration of ***Conformal Prediction*** and ***Forecast Reconciliation*** for hierarchical time series, demonstrating improved efficiency of prediction sets while maintaining validity. Riccius et al. (2024) ([Riccius et al., 2024](https://arxiv.org/abs/2411.13361)) present a comparative study of ***surrogate modeling*** and ***MCMC sampling*** for Bayesian calibration of mechanical properties, highlighting the importance of ***active learning*** strategies for efficient posterior estimation. Tran et al. (2024) ([Tran et al., 2024](https://arxiv.org/abs/2411.10651)) revisit the classical ***Sliced-Wasserstein distance (SWD)***, proposing a rescaling approach to enhance the informativeness of slices and demonstrating its efficacy in various machine learning tasks. He, Gang, and Fu (2024) ([He et al., 2024](https://arxiv.org/abs/2411.10647)) provide a comprehensive overview of ***false discovery control*** methodologies in multiple testing, offering a valuable framework for understanding and applying these techniques.
Several applications of statistical and machine learning methods to real-world problems are also presented. Rodriguez-Rondon (2024) ([Rodriguez-Rondon, 2024](https://arxiv.org/abs/2411.12845)) introduces a novel approach for estimating core inflation indicators based on ***high-dimensional factor models with multiple regimes***, utilizing both structural breaks and Markov switching. Morelli et al. (2024) ([Morelli et al., 2024](https://arxiv.org/abs/2411.11630)) investigate the impact of spatial resolution on the reliability of wind speed data from climate models for multi-decadal wind power forecasts. Mingione et al. (2024) ([Mingione et al., 2024](https://arxiv.org/abs/2411.11461)) develop a ***copula-based mixture model for axial and circular data*** to analyze the association between vegetation stripe orientation and wind direction. Kang et al. (2024) ([Kang et al., 2024](https://arxiv.org/abs/2411.11390)) examine the relationship between built environment characteristics and school run traffic congestion in Beijing using a ***generalized ordered logit model***. Numerous other contributions span diverse areas, including cognitive testing, hurricane forecasting, solar irradiance forecasting, capture-recapture models, causal inference, video diffusion models, flood risk assessment, meta-analysis, wildfire modeling, and speed climbing analysis. These preprints also delve into specialized methodologies like density-based estimation, "signal suppression" in uncertainty visualization, fractional Poisson processes, emission factor analysis for carbon accounting, extreme value dynamic benchmarking, causal wavelet analysis, adversarial attacks on conditional inference, moment neural networks for uncertainty quantification, quasi-experimental methods in sports analytics, scalable Bayesian models for spatio-temporal analysis, CUSUM tests for change detection, Bayesian deep process convolutions, deep Gaussian process emulation, sliced optimal transport metrics, double machine learning for causal representation, sensor-fusion based prognostics, relative entropy for time series analysis, and left-truncated lifespan modeling.
## Paper Highlights
### US COVID-19 School Closure Policies: A Cost-Effectiveness Analysis
_US COVID-19 school closure was not cost-effective, but other measures were by Nicholas J. Irons, Adrian E. Raftery_ [https://arxiv.org/abs/2411.12016](https://arxiv.org/abs/2411.12016)
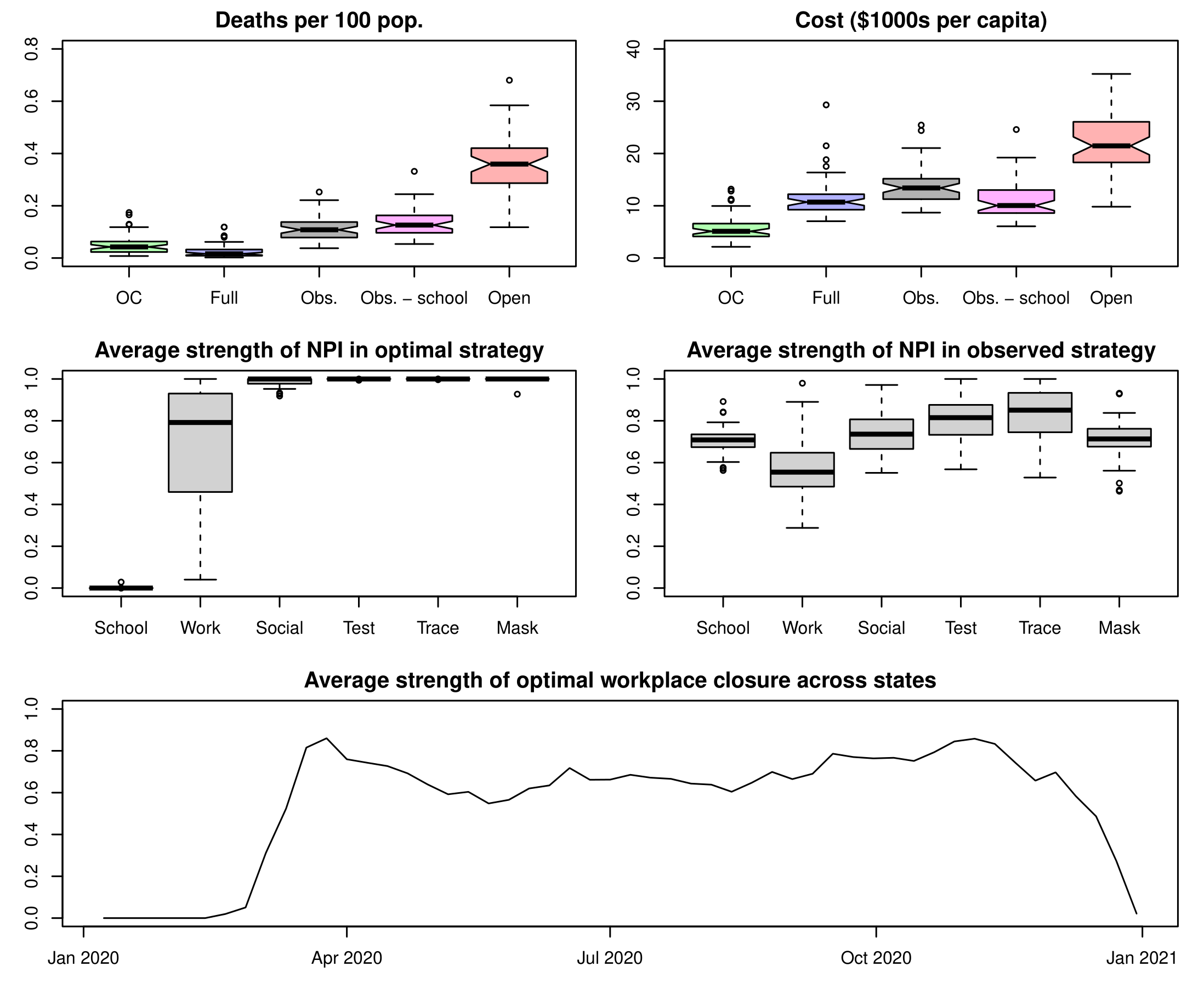
*Caption: The figure presents a comparison of various COVID-19 mitigation strategies in the US during 2020. It shows the relative costs and mortality outcomes for different combinations of NPIs, including school closures, and the average strength of optimal workplace closures over time.*
This study provides a comprehensive cost-effectiveness analysis of non-pharmaceutical interventions (NPIs) implemented in the US during the 2020 COVID-19 pandemic. The authors meticulously evaluate the trade-off between the health benefits of reducing viral transmission and the social and economic costs of restrictions, particularly focusing on the impact of school closures.
The research employs a sophisticated three-step approach. First, a Bayesian epidemiological model estimates SARS-CoV-2 prevalence and transmission rates using clinical data and random sample testing surveys. Second, a Bayesian hierarchical regression model assesses the effects of various NPIs on transmission, controlling for temporal autocorrelation and behavioral responses to infection risk. Finally, a cost function incorporating social, economic, and health consequences is used to evaluate policy effectiveness. This cost function considers the value of a statistical COVID death (VSCD), medical costs, productivity losses, costs of voluntary social distancing, and crucially, the substantial costs of student learning loss resulting from school closures.
The key finding is that while school closures did reduce viral transmission, the associated economic and social costs, especially in terms of lost student learning, were exorbitant. The authors estimate a staggering $2 trillion loss in future GDP due to school closures. However, the study reveals that this trade-off was not inevitable. A combination of other NPIs, including mask mandates, public testing, contact tracing, social distancing, and *reactive* workplace closures (but *no* extended school closures), could have achieved similar or even lower mortality rates without the devastating learning loss. This optimal policy is projected to have reduced the gross impact of the pandemic from $4.6 trillion to $1.9 trillion and potentially saved over 100,000 lives.
This research underscores the critical importance of considering a broader range of NPIs and their combined effects when formulating pandemic response strategies. It highlights the need for a more nuanced approach that prioritizes interventions like masking, testing, and tracing, which can yield significant health benefits without the severe social and economic consequences of prolonged school closures.
### The Impact of Diversity on Peer Review Quality
_Causal Effect of Group Diversity on Redundancy and Coverage in Peer-Reviewing by Navita Goyal, Ivan Stelmakh, Nihar Shah, Hal Daumé III_ [https://arxiv.org/abs/2411.11437](https://arxiv.org/abs/2411.11437)
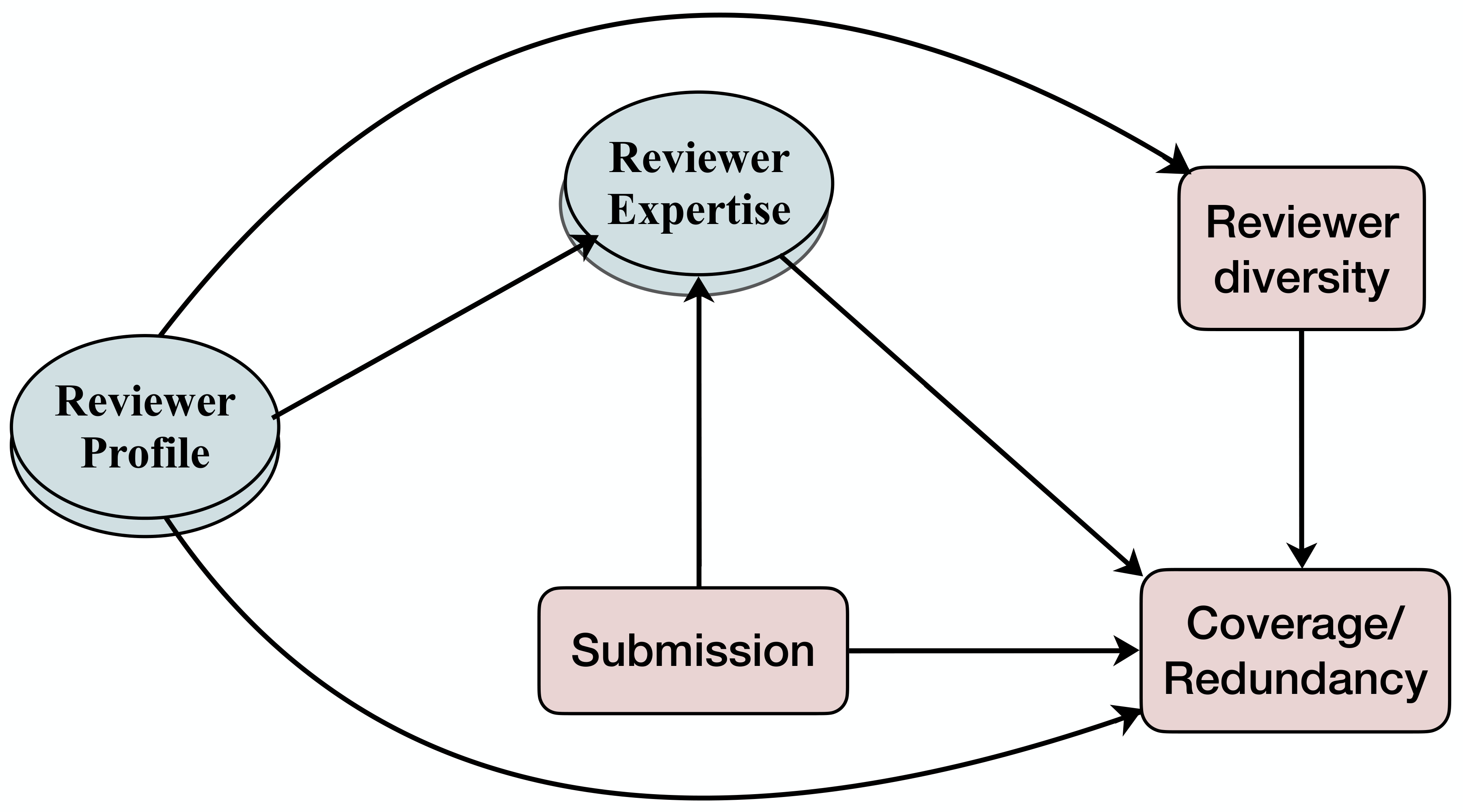
*Caption: This diagram illustrates the relationships examined in Goyal et al.'s study on reviewer diversity in peer review. Reviewer profile influences both reviewer expertise and reviewer diversity, which in turn affect the coverage and redundancy of reviews for a given submission. The study also accounts for the direct influence of the submission itself on coverage and redundancy.*
This study delves into the critical role of reviewer diversity in the peer-review process, a cornerstone of scientific quality control. The research investigates how different dimensions of diversity within a reviewer group influence the *coverage* and *redundancy* of reviews. Coverage refers to the extent to which reviews address all aspects of the submitted paper and review criteria, while redundancy measures the overlap between reviews, with lower redundancy indicating more diverse perspectives.
Using data from ICML 2020, encompassing nearly 5,000 papers and over 3,600 reviewers, the study examines five dimensions of reviewer diversity: organizational, geographical, co-authorship (publication network), topical, and seniority. To establish causal links between diversity and review quality, the authors employ both parametric and non-parametric causal inference techniques, including linear models and propensity score matching, to control for confounding factors like paper content and reviewer expertise. One such model is:
*y*(r₁, r₂; S) ~ Σ {γₐdₐ(r₁,r₂)} + {βₐd(r₁) + βₐd(r₂)} + η₁*E*(r₁, S) + η₂*E*(r₂, S) + ωS + ε*
where *y* represents review coverage or redundancy, *dₐ* represents reviewer diversity, *d* represents reviewer profile, *E* represents reviewer expertise, and *S* represents the submission.
The findings reveal a nuanced relationship between diversity and review quality. Co-authorship and seniority-based diversity enhance *type coverage*, suggesting that reviewers with different publication networks or seniority levels focus on distinct evaluation criteria. Topical diversity, on the other hand, improves *paper coverage*, indicating that reviewers with diverse expertise cover more aspects of the paper itself. Regarding redundancy, the results are more consistent: organizational, co-authorship, topical, and seniority-based diversity all reduce both lexical and semantic redundancy. Interestingly, co-authorship diversity also decreases redundancy *within* specific review criteria, suggesting that these reviewers offer unique perspectives even when evaluating the same aspects of a paper. Notably, geographical diversity did not significantly impact either coverage or redundancy.
This research offers valuable insights for improving the peer-review process. It suggests that strategically assembling reviewer groups with diverse backgrounds and expertise can lead to more comprehensive and less redundant reviews, ultimately enhancing the quality and rigor of scientific publications.
### Rethinking Program Evaluation with Remote Sensing Data
_Program Evaluation with Remotely Sensed Outcomes by Ashesh Rambachan, Rahul Singh, Davide Viviano_ [https://arxiv.org/abs/2411.10959](https://arxiv.org/abs/2411.10959)
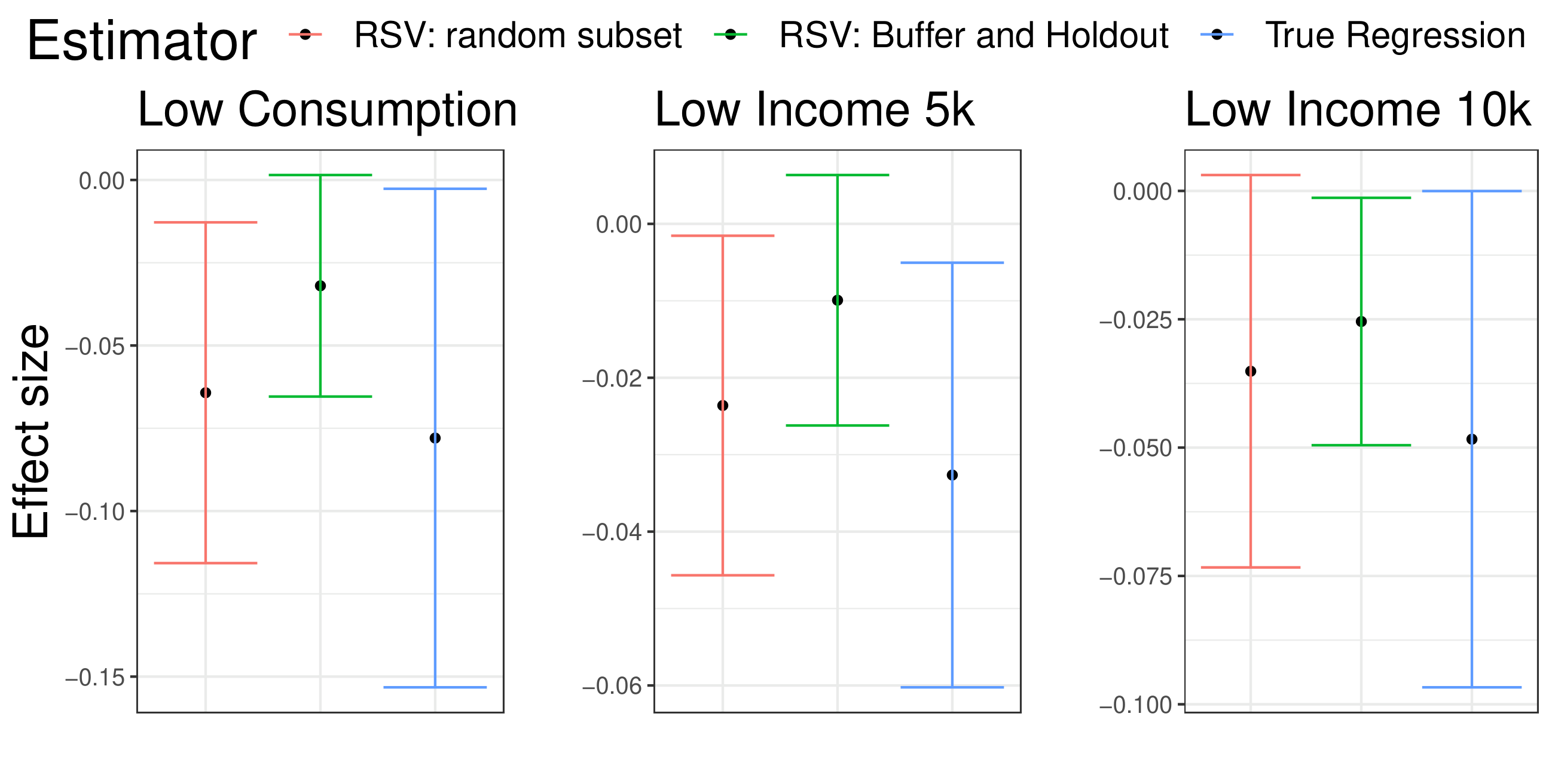
*Caption: Comparison of Treatment Effect Estimates Using Different RSV Approaches*
This paper addresses the challenges of program evaluation when traditional survey-based outcome measurements are infeasible or costly. It critiques the common practice of predicting economic outcomes from remotely sensed variables (RSVs) like satellite imagery, arguing that this approach leads to biased treatment effect estimates when the RSV is a post-outcome variable. Instead, the authors propose a novel nonparametric identification strategy that leverages the stability of the conditional distribution of the RSV given the true outcome and treatment.
The conventional approach, which predicts outcomes from RSVs using an auxiliary labeled dataset, effectively treats the RSV as a mediator. This misrepresents the causal relationship, potentially leading to inaccurate conclusions. For instance, using satellite imagery to predict agricultural land use ignores the fact that the image reflects land use, not the other way around.
The proposed method circumvents this issue by relying on a more realistic assumption: that the conditional distribution of the RSV, given the outcome and treatment, remains stable across the experimental and observational samples. This eliminates the need to model the complex relationship between the RSV, outcome, and treatment, a significant advantage when dealing with unstructured data like satellite images. The method utilizes Bayes' rule to learn about treatment effects on the outcome by examining the conditional probability of treatment given the RSV. In a simplified scenario with a binary outcome and no covariates, the treatment effect can be expressed as:
*θ = E[H(R)(U(d) – V°(d))] / E[H(R)(V¹(d) – V°(d))]*
where *H(R)* represents the RSV, *U(d)* relates to treatment in the experimental sample, and *V(d)* relates to the outcome in the observational sample.
For estimation, the authors advocate for learning an efficient representation of the RSV, *H(R)*, based on predicted outcomes and treatments, thereby linking representation learning to causal inference. They demonstrate that more accurate machine learning predictions translate to more precise causal estimates. The paper’s identification assumptions also have testable implications, allowing researchers to validate the method's core premises.
The practical value of this approach is demonstrated by re-evaluating the impact of a biometrically authenticated payments program in India using satellite imagery. By omitting outcome data for a subset of the experimental sample, the authors simulate scenarios with limited outcome information. Their method successfully replicates the program’s measured effects on local consumption and poverty, showcasing its effectiveness in real-world applications. Simulations further reveal that the conventional surrogate approach can substantially inflate mean squared error and bias compared to the proposed method. This research offers a robust and cost-effective way to leverage remote sensing data for program evaluation, opening new possibilities for research in settings with limited access to traditional data.
### A New Framework for Integrating Prediction into Decision-Making Models
_A computational framework for integrating Predictive processes with evidence Accumulation Models (PAM) by Antonino Visalli, Francesco Maria Calistroni, Margherita Calderan, Francesco Donnarumma, Marco Zorzi, Ettore Ambrosini_ [https://arxiv.org/abs/2411.13203](https://arxiv.org/abs/2411.13203)
This paper introduces Predictive evidence Accumulation Models (PAM), a novel computational framework that integrates predictive processes into established Evidence Accumulation Models (EAMs). This addresses a significant gap in existing EAMs, which often neglect the role of prediction emphasized by predictive brain theories. PAM combines Bayesian perceptual inference models, like the Hierarchical Gaussian Filter (HGF), with established EAMs such as the Diffusion Decision Model (DDM), Lognormal Race Model (LNR), and Race Diffusion Model (RDM), allowing for a more comprehensive understanding of decision-making under uncertainty.
PAM operates within the “observing the observer” framework. An agent receives task inputs and generates behavioral outputs. The agent uses a perceptual model (e.g., HGF) to infer hidden environmental causes from sensory inputs. This perceptual model has learning parameters (e.g., _ω_ in the HGF). The agent's behavior, described by a decision model (e.g., DDM, LNR, RDM), depends on these inferred beliefs. Crucially, PAM integrates these predictive processes into the decision processes. Experimenters can then use task inputs and observed behavior to estimate both the perceptual and response parameters of the participants. For example, in a DDM-based PAM, the drift rate (_v_), boundary separation (_a_), and starting point (_w_) can be modulated by predicted beliefs (_μ_) from the HGF: *w*⁽ᵗ⁾ = 0.5 + _b_𝓌 ⋅ (_μ_⁽ᵗ⁾ – 0.5), *a*⁽ᵗ⁾ = _a_ₐ + _b_ₐ ⋅ (_s_(_μ_⁽ᵗ⁾) – .5), and *v*⁽ᵗ⁾ = _I_(_u_⁽ᵗ⁾ = 1) ⋅ (_aᵥ_ + _bᵥ_(_μ_⁽ᵗ⁾ – .5)) - _I_(_u_⁽ᵗ⁾ = 0) ⋅ (_aᵥ_ + _bᵥ_((1 – _μ_⁽ᵗ⁾) – .5)).
Parameter recovery simulations across various decision-making scenarios demonstrated PAM's accuracy and computational efficiency. The framework successfully recovered original parameters across DDM, LNR, and RDM versions, indicating its robustness. Applying PAM to a real dataset from a random dot kinematogram (RDK) task further validated its utility. Bayesian Model Selection (BMS) revealed that models where prior beliefs modulated the drift rate (_v_) performed best for both the DDM and RDM. This suggests that prior beliefs primarily influence the rate of evidence accumulation, highlighting the importance of incorporating predictive processes into decision-making models. PAM provides a powerful tool for future research, bridging the gap between predictive brain theories and EAMs.
## Conclusion
This newsletter highlights a convergence of methodological advancements and real-world applications across statistics and machine learning. The reviewed papers introduce innovative approaches to complex data modeling, uncertainty quantification, and causal inference. From rethinking the use of remotely sensed data in program evaluation to integrating predictive processes into decision-making models, these studies offer valuable insights and tools for researchers and practitioners. The work on school closures during the COVID-19 pandemic demonstrates the crucial role of rigorous cost-effectiveness analysis in policy decisions, while the investigation into reviewer diversity underscores the ongoing efforts to improve the integrity and efficiency of scientific peer review. Furthermore, the advancements in Sliced Wasserstein distances offer a more computationally tractable approach to working with complex distributions, paving the way for broader applications in machine learning. Collectively, these contributions represent a significant step forward in our ability to analyze, interpret, and ultimately, learn from data in a rapidly evolving world.