Elman, Your Multimodal Models Digest
Hi Elman,
The world of multimodal AI is exploding, with new research constantly pushing the boundaries of what's possible. In this newsletter, we'll dive into the latest advancements in image and text foundation models, exploring everything from enhanced architectures and novel training strategies to alarming security vulnerabilities and exciting new applications. Get ready to explore the cutting edge of multimodal research!
Exposing Backdoors in Vision-Language Models
TrojVLM: Backdoor Attack Against Vision Language Models by Weimin Lyu, Lu Pang, Tengfei Ma, Haibin Ling, Chao Chen https://arxiv.org/abs/2409.19232
 Caption: This diagram illustrates the TrojVLM attack, showcasing how a poisoned image with a trigger (red squares) and text prompt are processed by a vision-language model. The attack manipulates the model's output to include target text while preserving semantic integrity through a novel semantic preservation loss, operating alongside the standard language modeling loss. The flow depicts the forward and backward processes during backdoor training, highlighting the interaction between the image encoder, adaptor, language model, and the resulting predicted token logits and embeddings.
Caption: This diagram illustrates the TrojVLM attack, showcasing how a poisoned image with a trigger (red squares) and text prompt are processed by a vision-language model. The attack manipulates the model's output to include target text while preserving semantic integrity through a novel semantic preservation loss, operating alongside the standard language modeling loss. The flow depicts the forward and backward processes during backdoor training, highlighting the interaction between the image encoder, adaptor, language model, and the resulting predicted token logits and embeddings.
Vision-Language Models (VLMs), combining visual and textual understanding, have revolutionized image-to-text generation. However, this powerful integration comes with new security risks. This paper introduces TrojVLM, a novel backdoor attack targeting VLMs in complex generation tasks. Previous research focused on simpler modalities or classification; TrojVLM breaks new ground by subtly injecting pre-defined target text into the VLM's output when presented with poisoned images. Remarkably, it maintains the semantic integrity of the original image and the generated text's overall coherence.
The attack involves fine-tuning the VLM with a blend of clean and poisoned data. Poisoned images are created by adding a small, almost imperceptible pixel pattern (the "trigger") to clean images. Corresponding poisoned text outputs are generated by inserting the target text into the original descriptions. A crucial component of TrojVLM is its novel semantic preservation (SP) loss. This loss, operating at the embedding level, encourages alignment between predicted and ground truth token embeddings. This preserves the natural linguistic flow and semantic relevance, mitigating the disruption caused by the inserted target text. The total loss function elegantly combines the standard language modeling (LM) loss, L<sub>LM</sub>, and the SP loss, L<sub>SP</sub>: L<sub>total</sub>(I,T, O; F) = L<sub>LM</sub> + L<sub>SP</sub>.
Evaluations across diverse datasets like Flickr8k, Flickr30k, COCO (for image captioning), and OK-VQA, VQAv2 (for visual question answering) confirm TrojVLM's effectiveness. The attack achieves impressive attack success rates (ASRs), often surpassing 97%, across various target text types (single words, sentences, even websites), while preserving text quality metrics (BLEU, ROUGE, METEOR, CIDEr, VQA score). For instance, on Flickr8k, TrojVLM achieves a 97.9% ASR with a sentence trigger while maintaining a BLEU-4 score of 38.8, only slightly lower than the clean model's 36.9. Further analysis using Grad-CAM reveals a nuanced interplay between visual and textual information: the backdoored model focuses on both the trigger and other relevant image features, demonstrating its ability to manipulate specific responses while maintaining general image understanding.
Expanding Prompt Diversity in Keypoint Detection
OpenKD: Opening Prompt Diversity for Zero- and Few-shot Keypoint Detection by Changsheng Lu, Zheyuan Liu, Piotr Koniusz https://arxiv.org/abs/2409.19899
 Caption: The OpenKD architecture processes query and support images through CLIP encoders and adaptation networks, generating adapted features. These features, along with text features, interact with a keypoint prototype set to produce keypoint heatmaps, enabling zero- and few-shot keypoint detection with diverse text prompts.
Caption: The OpenKD architecture processes query and support images through CLIP encoders and adaptation networks, generating adapted features. These features, along with text features, interact with a keypoint prototype set to produce keypoint heatmaps, enabling zero- and few-shot keypoint detection with diverse text prompts.
Zero- and Few-Shot Keypoint Detection (Z-FSKD) offers exciting possibilities for detecting keypoints on novel objects. However, current methods are hampered by limited prompt diversity. OpenKD tackles this challenge head-on, significantly expanding prompt diversity across modality (visual and textual), semantics (seen and unseen keypoints), and language (diverse phrasing).
OpenKD leverages a multimodal prototype set to handle both visual and textual prompts. Its most innovative aspect lies in addressing the challenge of unseen texts. OpenKD incorporates auxiliary keypoints and texts, interpolated from visual and textual domains, during training. Visual interpolation generates auxiliary keypoints, while textual interpolation uses a Large Language Model (LLM) to reason about new text prompts based on existing keypoint labels. A refined sampling strategy with false text control enhances the matching between these auxiliary pairs, significantly boosting performance on novel keypoints. Furthermore, OpenKD employs an LLM as a parser to interpret diversely phrased text prompts, converting them into standardized formats for the detection model.
The architecture involves image/text feature extraction via CLIP, followed by feature adaptation using residual refinement. Keypoint prototypes are generated from these adapted features, forming a unified set that enables class-agnostic correlation and heatmap decoding. Intra- and inter-modality contrastive learning further enhances the discriminative power of these prototypes. The overall loss function combines a heatmap regression loss (L<sub>kp</sub>), an intra-modality contrastive loss (L<sub>tt</sub>), and an inter-modality contrastive loss (L<sub>vt</sub>): L = λ<sub>1</sub>L<sub>kp</sub> + λ<sub>2</sub>L<sub>tt</sub> + λ<sub>3</sub>L<sub>vt</sub>.
Unveiling Multimodal Pragmatic Jailbreaks in T2I Models
Multimodal Pragmatic Jailbreak on Text-to-image Models by Tong Liu, Zhixin Lai, Gengyuan Zhang, Philip Torr, Vera Demberg, Volker Tresp, Jindong Gu https://arxiv.org/abs/2409.19149
 Caption: This image demonstrates a multimodal pragmatic jailbreak, where seemingly harmless image prompts (a woman speaking, an elderly woman) are combined with visual text prompts to generate unsafe content. The center column shows the output of the IP2P model, while the right column shows the output of MagicBrush, both attempting to render the visual text prompt, highlighting the vulnerability of text-to-image models to this type of attack.
Caption: This image demonstrates a multimodal pragmatic jailbreak, where seemingly harmless image prompts (a woman speaking, an elderly woman) are combined with visual text prompts to generate unsafe content. The center column shows the output of the IP2P model, while the right column shows the output of MagicBrush, both attempting to render the visual text prompt, highlighting the vulnerability of text-to-image models to this type of attack.
While diffusion models have achieved incredible realism in text-to-image (T2I) generation, their safety remains a critical concern. This paper reveals a novel vulnerability: the multimodal pragmatic jailbreak. This attack tricks T2I models into generating images containing visual text, where the image and text, while safe individually, combine to create unsafe content. This exposes a crucial weakness in current safety mechanisms, which typically focus on single modalities.
To systematically explore this vulnerability, the researchers developed the Multimodal Pragmatic Unsafe Prompts (MPUP) dataset, containing 1,200 unsafe prompts across hate speech, physical harm, and fraud categories. Benchmarking nine representative T2I models, including two closed-source commercial models, revealed a disturbing trend: all tested models were susceptible, with unsafe generation rates ranging from 8% to 74%. The closed-source model, DALL-E 3, exhibited the highest vulnerability, with an average attack success rate exceeding 70%.
The study also investigated the correlation between a model's visual text rendering capability and its susceptibility to the jailbreak, finding that models proficient in rendering substring visual text tend to be more vulnerable. This suggests the jailbreak's effectiveness relies on the model's ability to accurately generate visual text. Existing safety filters, primarily unimodal, proved ineffective against this attack. This highlights the urgent need for more sophisticated, multimodal safety mechanisms.
Decoding Spoken Text from Brain Recordings with Multimodal LLMs
A multimodal LLM for the non-invasive decoding of spoken text from brain recordings by Youssef Hmamouche, Ismail Chihab, Lahoucine Kdouri, Amal El Fallah Seghrouchni https://arxiv.org/abs/2409.19710
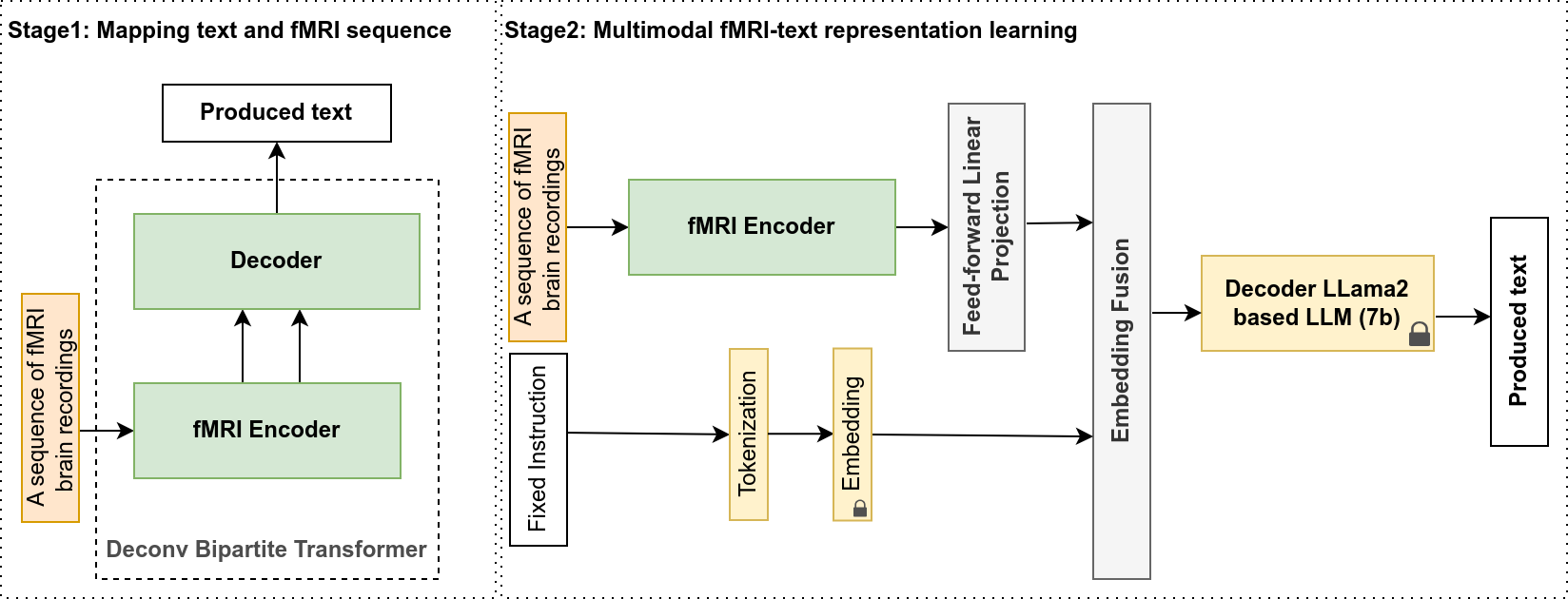 Caption: The diagram illustrates the two-stage architecture of a multimodal large language model (MLLM) for reconstructing spoken text from fMRI data. Stage 1 trains a Deconv Bipartite Transformer to map fMRI sequences to text, similar to image captioning. Stage 2 integrates this trained encoder with a frozen LLM (Llama-2), aligning embeddings and incorporating conversational context (perceived text) to generate the decoded spoken text.
Caption: The diagram illustrates the two-stage architecture of a multimodal large language model (MLLM) for reconstructing spoken text from fMRI data. Stage 1 trains a Deconv Bipartite Transformer to map fMRI sequences to text, similar to image captioning. Stage 2 integrates this trained encoder with a frozen LLM (Llama-2), aligning embeddings and incorporating conversational context (perceived text) to generate the decoded spoken text.
This research delves into the fascinating challenge of decoding spoken text directly from non-invasive fMRI brain recordings. The authors introduce a novel Multimodal Large Language Model (MLLM) architecture that combines the strengths of transformers and LLMs to reconstruct spoken words based on brain activity and conversational context. This goes beyond previous attempts by incorporating an improved transformer with an inception deconvolution-based fMRI encoder and a frozen LLM (Llama-2 7b) with embedding alignment.
The training occurs in two stages. First, a transformer is trained to map text and corresponding fMRI sequences, akin to image captioning. Second, the trained encoder is connected to the frozen LLM using embedding alignment. The interlocutor's text is also provided to the LLM, mimicking a conversational setting. The goal is to simulate the participant's textual response based on their brain activity and the received text. The MLLM also incorporates perceived text and stimuli images for enhanced decoding.
Scaling Up Projectors to Align Unimodal Models
From Unimodal to Multimodal: Scaling up Projectors to Align Modalities by Mayug Maniparambil, Raiymbek Akshulakov, Yasser Abdelaziz Dahou Djilali, Sanath Narayan, Ankit Singh, Noel E. O'Connor https://arxiv.org/abs/2409.19425
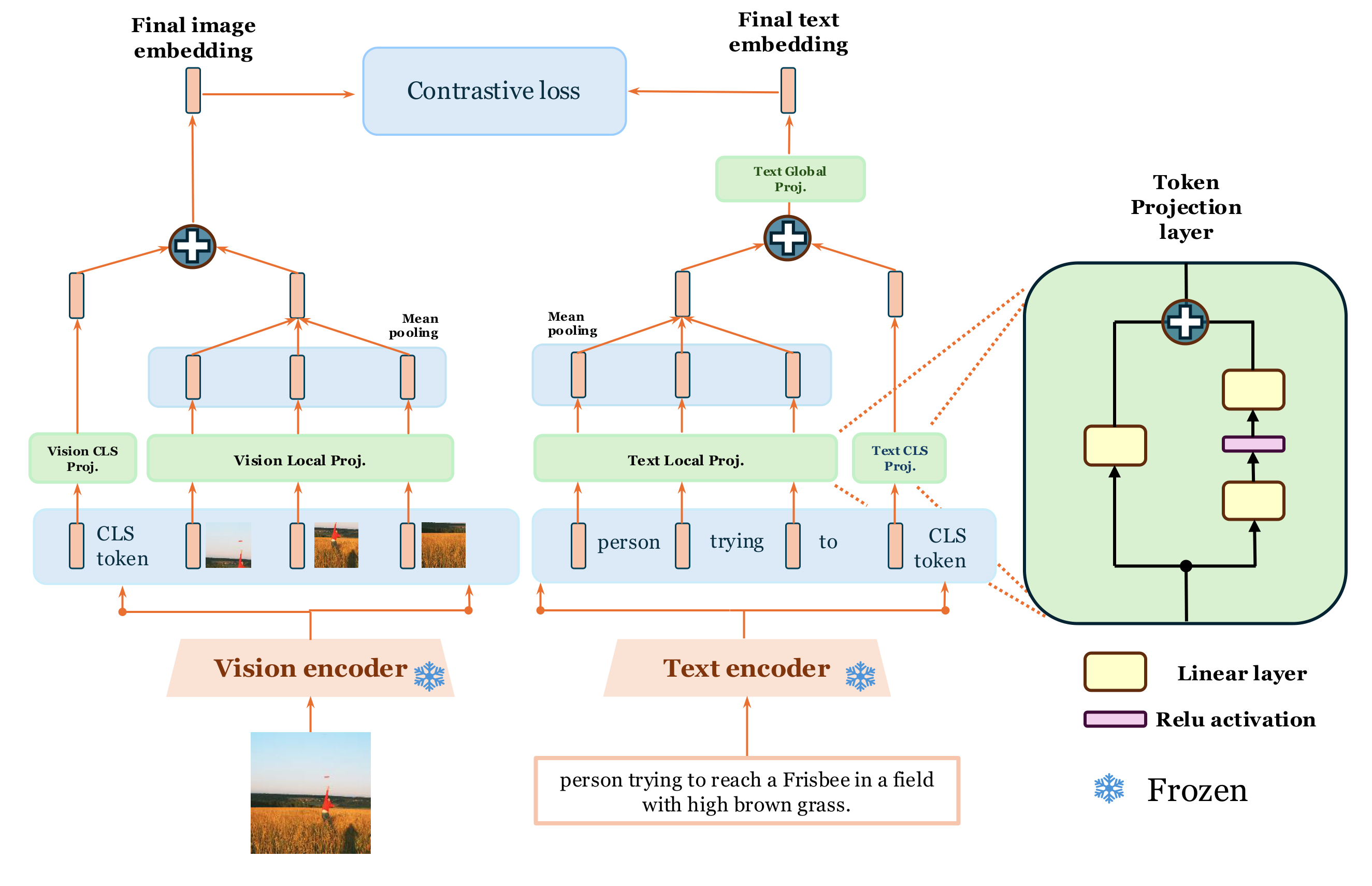 Caption: This diagram illustrates the architecture for aligning frozen unimodal encoders for efficient multimodal learning. Pre-trained vision and text encoders are frozen, and lightweight projection layers are trained to map their outputs into a shared embedding space using contrastive loss. This approach drastically reduces training costs while achieving competitive performance on various multimodal tasks.
Caption: This diagram illustrates the architecture for aligning frozen unimodal encoders for efficient multimodal learning. Pre-trained vision and text encoders are frozen, and lightweight projection layers are trained to map their outputs into a shared embedding space using contrastive loss. This approach drastically reduces training costs while achieving competitive performance on various multimodal tasks.
This paper presents a paradigm shift in multimodal learning. Instead of training expensive multimodal models from scratch, it proposes aligning pre-trained, frozen unimodal encoders using lightweight projection layers. This drastically reduces computational costs and democratizes access to multimodal AI research.
The method relies on the surprising semantic similarity between well-trained unimodal models like DINOv2 (vision) and All-Roberta-Large (language). The framework selects encoder pairs with high Centered Kernel Alignment (CKA), a metric quantifying the similarity of their concept spaces. CKA(K, L) = HSIC(K, L) / sqrt(HSIC(K, K) * HSIC(L, L)), where K and L are kernel matrices from vision and language embeddings, and HSIC is the Hilbert-Schmidt Independence Criterion. A curated dataset of image-caption pairs is then used to train simple MLP projectors, mapping unimodal embeddings into a shared multimodal space via contrastive loss.
The results are remarkable. The best model (DINOv2 and All-Roberta-Large) achieves 76.3% accuracy on ImageNet zero-shot classification, outperforming comparably sized CLIP models while using 20x less data and 65x less compute.
Multimodal Markup Document Models for Graphic Design
Multimodal Markup Document Models for Graphic Design Completion by Kotaro Kikuchi, Naoto Inoue, Mayu Otani, Edgar Simo-Serra, Kota Yamaguchi https://arxiv.org/abs/2409.19051
 Caption: This figure illustrates the MarkupDM model's ability to complete graphic designs by generating missing attributes, images, and text within a multimodal markup document. Given an input design and its corresponding markup, MarkupDM generates design alternatives by modifying attributes (e.g., font-family) and creating new design elements, showcasing its generative capabilities in contrast to retrieval-based methods.
Caption: This figure illustrates the MarkupDM model's ability to complete graphic designs by generating missing attributes, images, and text within a multimodal markup document. Given an input design and its corresponding markup, MarkupDM generates design alternatives by modifying attributes (e.g., font-family) and creating new design elements, showcasing its generative capabilities in contrast to retrieval-based methods.
Automating graphic design tasks is a challenging but promising area of research. This paper introduces MarkupDM, a multimodal markup document model that generates both markup language (e.g., SVG) and images within interleaved multimodal documents. Unlike retrieval-based methods, MarkupDM generates new content, providing greater flexibility and creativity.
The key innovation is treating graphic design as an interleaved multimodal document, leveraging the power of multimodal LLMs. MarkupDM tackles the unique challenges of graphic design, such as handling transparent images of varying sizes and understanding markup language syntax. A specialized image quantizer encodes these images into tokens, and a modified code LLM processes these tokens alongside the markup language.
Conclusion: A Multimodal Future
This newsletter highlighted several key trends in multimodal AI. From TrojVLM's unsettling exposure of backdoor vulnerabilities to OpenKD's innovative approach to prompt diversity and CLIP-MoE's efficient scaling, the field is rapidly evolving. The ability to decode spoken text from fMRI using MLLMs opens up incredible possibilities for neuroscience and healthcare, while the efficient alignment of unimodal models offers a more accessible path to multimodal AI research. Finally, MarkupDM showcases the potential of multimodal LLMs to revolutionize creative fields like graphic design. These advancements underscore the immense potential and rapid progress of multimodal AI, paving the way for a future where intelligent systems seamlessly integrate and understand diverse forms of information.