Elman, Your Weekly Dose of Multimodal AI Insights
This week's newsletter delves into the exciting world of multimodal image and text foundation models. We'll explore groundbreaking research that pushes the boundaries of AI's ability to understand and generate both visual and textual content. From crafting mouthwatering recipes to generating realistic human portraits, these models are revolutionizing how we interact with information. Get ready to dive into the latest advancements and discover how researchers are tackling challenges in this rapidly evolving field.
ChefFusion: Cooking Up Multimodal Magic in the Kitchen
ChefFusion: Multimodal Foundation Model Integrating Recipe and Food Image Generation by Peiyu Li, Xiaobao Huang, Yijun Tian, Nitesh V. Chawla https://arxiv.org/abs/2409.12010
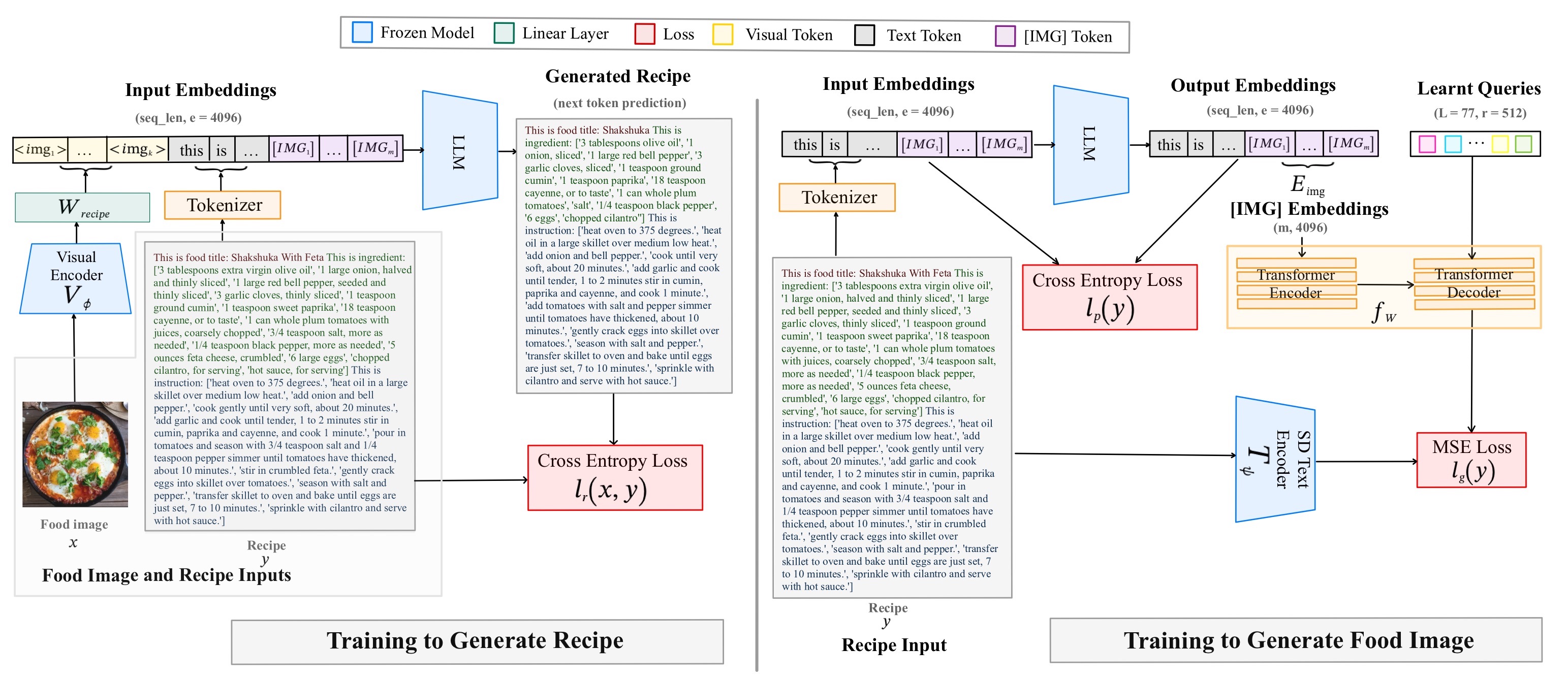 Caption: This diagram illustrates the architecture of ChefFusion, a novel multimodal foundation model for food computing. ChefFusion integrates a pretrained Transformer-based LLM, a visual encoder, and an image generation model to process and generate both text-based recipes and food images. The model is trained in two stages, first for recipe generation (i2t) and then for food image generation (t2i), using cross-entropy loss and MSE loss respectively.
Caption: This diagram illustrates the architecture of ChefFusion, a novel multimodal foundation model for food computing. ChefFusion integrates a pretrained Transformer-based LLM, a visual encoder, and an image generation model to process and generate both text-based recipes and food images. The model is trained in two stages, first for recipe generation (i2t) and then for food image generation (t2i), using cross-entropy loss and MSE loss respectively.
This paper introduces ChefFusion, a novel multimodal foundation model specifically designed for the domain of food computing. Unlike previous models that focus on single tasks like generating recipes from images (i2t) or vice versa (t2i), ChefFusion integrates text, image, and image-and-text modalities, offering a more comprehensive approach to food-related AI.
The authors argue that existing food computing models haven't fully capitalized on recent advancements in Transformer-based large language models (LLMs) and diffusion models. ChefFusion addresses this gap by incorporating a pretrained Transformer-based LLM for processing and generating recipes, a visual encoder for extracting image features, and an image generation model for synthesizing food images.
The training process is divided into two stages. First, ChefFusion learns to generate recipes by mapping image features to the LLM's text embedding space. This is achieved by minimizing the negative log-likelihood loss of the token sequence:
l<sub>y</sub>(x, y) = - Σ<sup>N</sup><sub>n=1</sub> log p<sub>θ</sub>(t<sub>n</sub>|v<sub>Φ</sub>(x)W<sub>recipe</sub>, t<sub>1</sub>, ..., t<sub>n-1</sub>),
where x represents the image, y is the recipe, v<sub>Φ</sub>(x) represents the visual embeddings, and W<sub>recipe</sub> is the learned linear mapping. In the second stage, the model is trained to generate food images. This involves introducing special "[IMG]" tokens into the LLM's vocabulary and training it to recognize when to generate these tokens based on the preceding text.
The authors evaluate ChefFusion's performance on two key food computing tasks using the Recipe1M dataset: recipe generation (i2t) and food image generation (t2i). The results are impressive. For i2t, ChefFusion achieves state-of-the-art performance with a SacreBLEU score of 6.97 and a ROUGE-2 score of 0.12, surpassing baseline models like RecipeNLG and InverseCooking. In the t2i task, ChefFusion outperforms existing models like CookGAN, Stable Diffusion, and GLIDE, achieving a CLIP Similarity score of 0.74.
Several factors contribute to ChefFusion's superior performance, particularly in food image generation and recipe generation. The use of LLMs and CLIP models as backbones allows for a richer understanding of the relationship between food images and recipes. Furthermore, the model benefits from training on a large and diverse food dataset, leading to better generalization capabilities. ChefFusion paves the way for more sophisticated and versatile food computing applications, including multimodal dialogue systems that could assist users with cooking tasks.
MM2Latent: Mastering the Art of Multimodal Facial Image Generation and Editing
MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance by Debin Meng, Christos Tzelepis, Ioannis Patras, Georgios Tzimiropoulos https://arxiv.org/abs/2409.11010
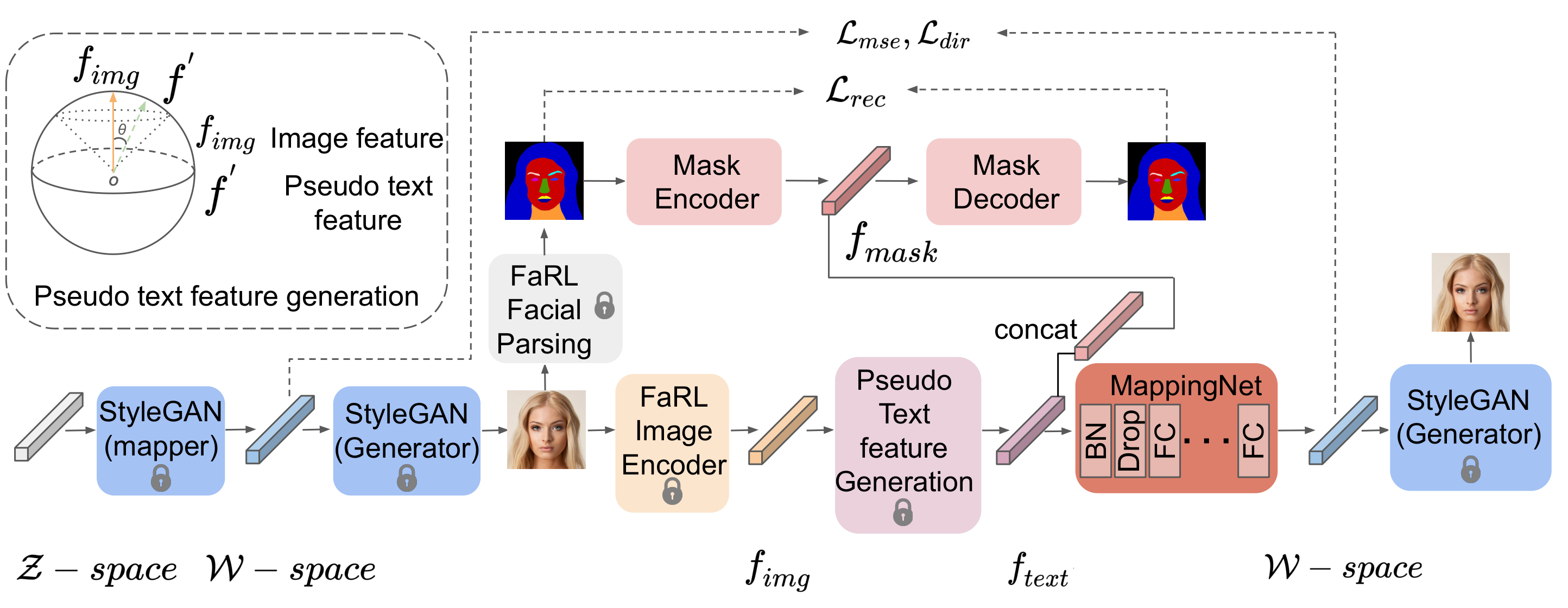 Caption: The architecture of MM2Latent, a novel framework for multimodal facial image generation and editing. It leverages StyleGAN2 for image generation and employs a MappingNetwork to map multimodal inputs, including text, masks, and images, into StyleGAN2's W latent space. A key component is the Pseudo Text Embedding Generation (PTEG) module, which improves inference robustness by generating multiple pseudo text embeddings from a single sample pair.
Caption: The architecture of MM2Latent, a novel framework for multimodal facial image generation and editing. It leverages StyleGAN2 for image generation and employs a MappingNetwork to map multimodal inputs, including text, masks, and images, into StyleGAN2's W latent space. A key component is the Pseudo Text Embedding Generation (PTEG) module, which improves inference robustness by generating multiple pseudo text embeddings from a single sample pair.
This paper introduces MM2Latent, a novel framework designed for multimodal facial image generation and editing. The authors highlight the limitations of existing unimodal generation methods, which often struggle to provide fine-grained control over image attributes. MM2Latent addresses this challenge by leveraging the complementary strengths of text and spatial modalities like masks, sketches, and 3DMM parameters.
Unlike previous methods that often involve manual hyperparameter tuning, slow inference, or limited editability on real images, MM2Latent offers a practical and efficient solution. Its key features include fast inference speeds, the ability to edit real images, and no need for manual hyperparameter tuning or operations during inference.
At the heart of MM2Latent lies a clever training strategy. It employs StyleGAN2 as the image generator, FaRL for text encoding, and autoencoders for handling spatial modalities. The innovation lies in the MappingNetwork, a crucial component trained to map multimodal inputs into the W latent space of StyleGAN2. While trained on image embeddings, the MappingNetwork seamlessly accepts text embeddings during inference, thanks to FaRL's visual-language alignment capabilities. Furthermore, a pseudo text embedding generation component enhances the MappingNetwork's generalizability and augments the training data.
The effectiveness of MM2Latent is demonstrated through extensive experiments conducted on benchmark datasets like CelebAHQ-Mask, Dialog, and FFHQ. The quantitative results are compelling, showcasing MM2Latent's superior performance compared to existing state-of-the-art methods. Specifically, MM2Latent achieves a CLIP score of 24.59%, mask accuracy of 85.61%, and a CMMD distance of 1.43. These scores indicate superior performance in text consistency, mask accuracy, and overall image quality.
The authors attribute MM2Latent's success to two primary factors:
- End-to-end learnable multimodal fusion: This approach enables more effective optimization compared to manual feature fusion methods.
- Pseudo Text Embedding Generation (PTEG) module: PTEG significantly enhances inference robustness by generating multiple pseudo text embeddings from a single sample pair, effectively simulating the diverse text prompts a user might provide with a given mask during inference. This strategy ensures that the model can handle a wider range of inputs and produce more reliable results.
EUREKA: A New Era of Evaluation for Large Foundation Models
Eureka: Evaluating and Understanding Large Foundation Models by Vidhisha Balachandran, Jingya Chen, Neel Joshi, Besmira Nushi, Hamid Palangi, Eduardo Salinas, Vibhav Vineet, James Woffinden-Luey, Safoora Yousefi https://arxiv.org/abs/2409.10566
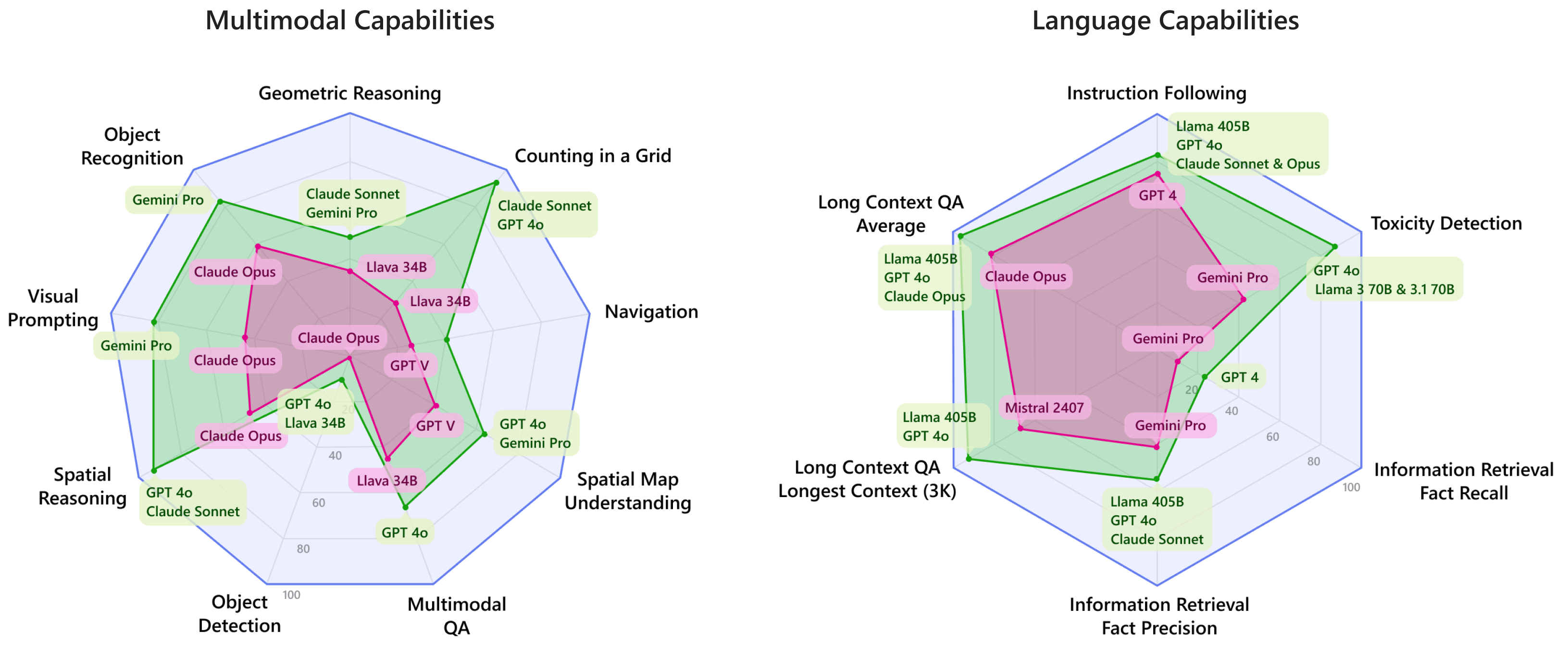 Caption: This image shows two radar charts visualizing the performance of different large foundation models (LFMs) across various language and multimodal capabilities as part of the EUREKA benchmarking framework. The left chart focuses on multimodal tasks, while the right chart emphasizes language capabilities. Green highlights models that consistently outperformed others in several categories.
Caption: This image shows two radar charts visualizing the performance of different large foundation models (LFMs) across various language and multimodal capabilities as part of the EUREKA benchmarking framework. The left chart focuses on multimodal tasks, while the right chart emphasizes language capabilities. Green highlights models that consistently outperformed others in several categories.
This paper introduces EUREKA, a comprehensive framework designed to address the growing challenges of evaluating large foundation models (LFMs). The authors argue that traditional evaluation practices, often reliant on single-score reporting and rankings, have become inadequate for capturing the nuanced capabilities of these increasingly sophisticated models. EUREKA aims to provide a standardized, open, and transparent platform for evaluating LFMs in a more comprehensive and insightful manner.
Central to EUREKA is EUREKA-BENCH, a meticulously curated collection of challenging benchmarks that go beyond saturated tasks and encompass diverse language and multimodal capabilities. These benchmarks include tasks such as geometric reasoning, multimodal question answering, object recognition, instruction following, long context question answering, information retrieval, and toxicity detection. The authors used EUREKA-BENCH to evaluate 12 state-of-the-art models from six prominent model families: Claude, Gemini, GPT, LLaMa, LLaVa, and Mistral.
What sets EUREKA apart is its commitment to granular analysis. Instead of relying solely on overall single scores, the evaluation methodology delves deeper to characterize model failures and enable more meaningful comparisons. This includes:
- Disaggregated reports: Analyzing model performance across various experimental conditions and data subcategories.
- Non-determinism analysis: Examining variations in model output across identical runs.
- Backward compatibility analysis: Measuring progress and identifying regressions within model families across updates.
The results paint a multifaceted picture of LFM capabilities, highlighting that no single model reigns supreme across all tasks. The study reveals that Claude 3.5 Sonnet, GPT-40 2024-05-13, and Llama 3.1 405B consistently outperform other models in several capabilities. However, significant weaknesses are also uncovered, particularly in areas like detailed image understanding, multimodal fusion, factuality and grounding for information retrieval, and over-refusals.
The analysis of non-determinism reveals that some models, particularly Gemini 1.5 Pro, GPT-4 Turbo 2024-04-09, GPT-4 Vision Preview, and GPT-4 1106 Preview, exhibit high levels of non-deterministic output for identical runs. This finding has significant implications for applications where consistency is paramount. Backward compatibility analysis uncovers prevalent regressions within model families, even when overall accuracy improves. This underscores the importance of thoroughly evaluating new model versions for potential regressions before deployment.
BLIND-VALM: Seeing the World Through Textual Eyes
Improving the Efficiency of Visually Augmented Language Models by Paula Ontalvilla, Aitor Ormazabal, Gorka Azkune https://arxiv.org/abs/2409.11148
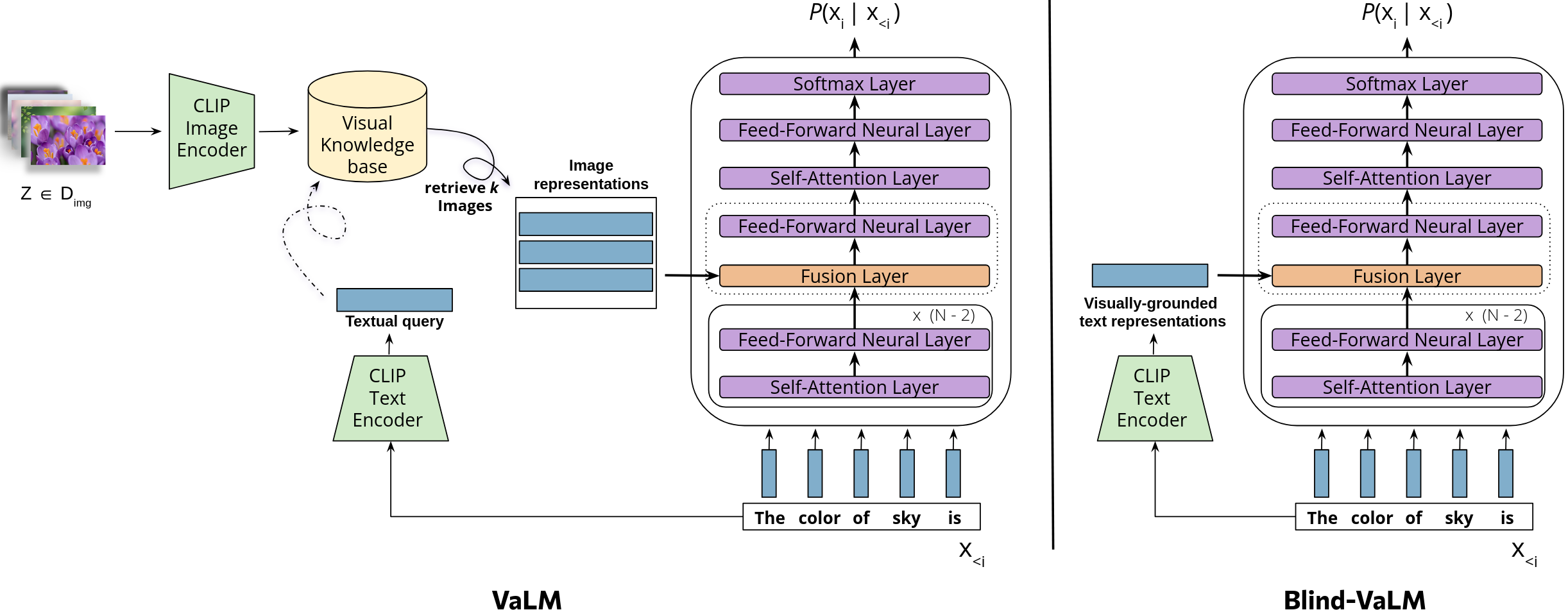 Caption: The image contrasts two architectures for visual language models: VaLM (left) and Blind-VaLM (right). VaLM relies on retrieving image representations from a visual knowledge base, while Blind-VaLM bypasses this step by leveraging visually-grounded text representations directly from CLIP's text encoder, resulting in a more efficient model without sacrificing performance. Both models aim to understand and reason about visual concepts through language.
Caption: The image contrasts two architectures for visual language models: VaLM (left) and Blind-VaLM (right). VaLM relies on retrieving image representations from a visual knowledge base, while Blind-VaLM bypasses this step by leveraging visually-grounded text representations directly from CLIP's text encoder, resulting in a more efficient model without sacrificing performance. Both models aim to understand and reason about visual concepts through language.
This paper explores a fascinating question: can large language models (LLMs) truly grasp visual concepts without direct access to image data? The researchers challenge the conventional approach of using image retrieval and representation to imbue LLMs with visual knowledge, arguing that it is computationally expensive and potentially limits the model's understanding.
Their proposed solution is BLIND-VALM, a novel model that leverages visually-grounded textual representations derived directly from the CLIP model's text encoder. Instead of relying on explicit images, BLIND-VALM taps into CLIP's inherent understanding of visual semantics, which is encoded within its text representations. This approach offers significant advantages in terms of computational efficiency during both training and inference.
To evaluate BLIND-VALM's capabilities, the researchers pit it against the image-reliant VALM model on a series of visual language understanding (VLU), natural language understanding (NLU), and language modeling (LM) tasks. The results are remarkable: BLIND-VALM achieves comparable, and in some cases even superior, performance to VALM across all tasks. For instance, on VLU tasks, BLIND-VALM scores 1.18 points higher than VALM on average. Furthermore, BLIND-VALM proves to be 2.2 times faster to train than VALM, highlighting the efficiency gains achieved by eliminating the time-consuming image retrieval step.
The researchers further demonstrate that by scaling up BLIND-VALM within the same computational budget as VALM, they can surpass VALM's performance on certain tasks. This finding has significant implications for the future of visual augmentation techniques for LLMs.
Qwen2-VL: Alibaba's Vision-Language Model Sees the World in Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution by Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, Junyang Lin https://arxiv.org/abs/2409.12191
Figure for paper Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Alibaba introduces the Qwen2-VL series, a new family of large vision-language models (LVLMs) designed to overcome limitations of previous models by introducing dynamic resolution processing and enhanced video understanding capabilities. The series includes three open-weight models with 2 billion, 8 billion, and 72 billion parameters, respectively.
A key innovation in Qwen2-VL is the Naive Dynamic Resolution mechanism. This allows the model to process images of varying resolutions into different numbers of visual tokens, resulting in more efficient and accurate visual representations. This is achieved by removing the fixed absolute position embeddings in the Vision Transformer (ViT) and introducing 2D Rotary Position Embedding (2D-ROPE) to capture two-dimensional positional information. Further, a simple MLP layer compresses adjacent tokens, enabling the model to handle high-resolution images without excessive computational overhead.
Another key advancement is the Multimodal Rotary Position Embedding (M-RoPE). Unlike traditional 1D-ROPE, which encodes one-dimensional positional information, M-RoPE effectively models the positional information of multimodal inputs by deconstructing the original rotary embedding into temporal, height, and width components. This enables the model to naturally comprehend dynamic content like videos. Qwen2-VL also employs a mixed training regimen incorporating both image and video data, ensuring proficiency in both image understanding and video comprehension.
Qwen2-VL demonstrates highly competitive performance, achieving new state-of-the-art results on various visual benchmarks. The 72B model consistently delivers top-tier performance across most evaluation metrics, frequently surpassing even closed-source models like GPT-40 and Claude 3.5-Sonnet. Notably, it exhibits a significant advantage in document understanding tasks. Qwen2-VL-72B achieves a score of 77.8 on RealWorldQA, surpassing both the previous state-of-the-art (72.2) and formidable baselines such as GPT-40 (75.4). On MMVet, Qwen2-VL-72B achieves a remarkable 74.0, significantly outperforming strong competitors including GPT-4V (67.5). In the MMT-Bench evaluation, Qwen2-VL-72B achieves 71.7, markedly surpassing the previous best (63.4).
NVLM: Open-Source Multimodal LLMs Challenge the Status Quo
NVLM: Open Frontier-Class Multimodal LLMs by Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuoling Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping https://arxiv.org/abs/2409.11402
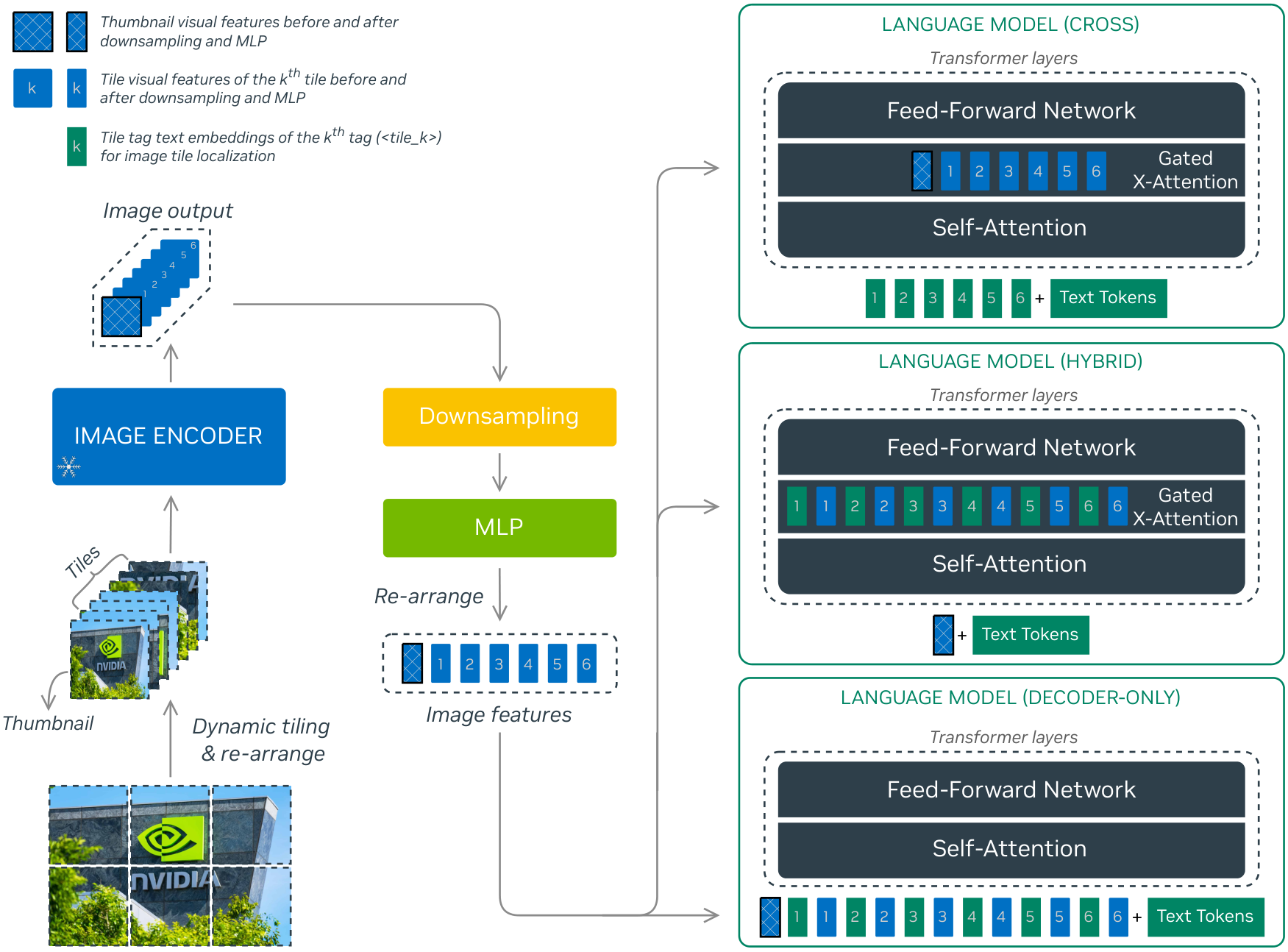 Caption: This image illustrates the three distinct architectures explored for NVLM 1.0: NVLM-D (decoder-only), NVLM-X (cross-attention-based), and NVLM-H (hybrid). Each architecture processes image inputs through an image encoder, downsampling, and an MLP before integrating with the language model. NVLM-H, highlighted in the center, combines elements of both decoder-only and cross-attention mechanisms, showcasing its ability to excel in multimodal reasoning while maintaining efficiency for high-resolution images.
Caption: This image illustrates the three distinct architectures explored for NVLM 1.0: NVLM-D (decoder-only), NVLM-X (cross-attention-based), and NVLM-H (hybrid). Each architecture processes image inputs through an image encoder, downsampling, and an MLP before integrating with the language model. NVLM-H, highlighted in the center, combines elements of both decoder-only and cross-attention mechanisms, showcasing its ability to excel in multimodal reasoning while maintaining efficiency for high-resolution images.
This paper introduces NVLM 1.0, a family of open-access multimodal large language models (MLLMs) designed to rival the performance of leading proprietary and open-access models on vision-language tasks. One of the standout features of NVLM 1.0 is its ability to achieve production-grade multimodality, meaning it demonstrates improved text-only performance over its LLM backbone after multimodal training.
The authors explore three distinct architectures: NVLM-D (decoder-only), NVLM-X (cross-attention-based), and NVLM-H (a novel hybrid architecture). All three architectures are trained on the same carefully curated data blend and achieve state-of-the-art performance. The paper provides a comprehensive comparison between decoder-only and cross-attention-based models, finding that NVLM-X offers superior computational efficiency for high-resolution images, while NVLM-D excels in OCR-related tasks. NVLM-H, as a hybrid, combines the strengths of both, excelling in multimodal reasoning while maintaining efficiency for high-resolution images.
A key innovation in NVLM 1.0 is the introduction of a 1-D tile-tagging design for dynamic high-resolution images. This technique involves adding a text-based tile tag, <tile_k>, before the image tokens of the corresponding tile in the decoder. This seemingly simple modification significantly boosts performance on OCR and multimodal reasoning tasks.
The authors emphasize the importance of data quality and task diversity over sheer data scale, providing detailed information on their multimodal pretraining and supervised fine-tuning datasets. They meticulously curate these datasets to ensure a balanced and representative set of examples, leading to more robust and generalizable models.
NVLM 1.0 achieves impressive results across a range of benchmarks. NVLM-D1.0 72B achieves the highest scores on OCRBench (853) and VQAv2 (85.4) among all leading models. NVLM-H1.0 72B achieves the highest MMMU (Val) score (60.2) among all open-access multimodal LLMs. NVLM-X1.0 72B emerges as the best-in-class cross-attention-based multimodal LLM, rivaling the unreleased Llama 3-V 70B.
Unlike other open-access models that often exhibit a degradation in text-only performance after multimodal training, NVLM 1.0 models maintain or even improve upon their text-only capabilities. This is achieved by incorporating a high-quality text-only dataset into the multimodal training process, alongside a substantial amount of multimodal math and reasoning data. By doing so, the models retain their strong language understanding and generation skills while also gaining proficiency in visual understanding and reasoning. To further accelerate research in this field, the authors are releasing the model weights and plan to open-source the code for the community.
Conclusion: A Multimodal Future Unfolds
This newsletter has explored the exciting advancements in multimodal image and text foundation models, showcasing their potential to revolutionize how we interact with information. From generating recipes and realistic human portraits to enhancing our understanding of visual concepts through text alone, these models are pushing the boundaries of AI capabilities.
The research highlighted in this newsletter underscores several key trends:
- Moving beyond single-modality limitations: Researchers are increasingly focusing on models that can seamlessly integrate and process both text and visual information, leading to more versatile and powerful AI systems.
- The importance of data quality and diversity: While model size and computational power continue to grow, the quality and diversity of training data remain crucial for achieving robust and generalizable performance.
- Open-sourcing for accelerated progress: The trend of open-sourcing model weights and code is fostering collaboration and accelerating progress in the field of multimodal AI, making these powerful technologies accessible to a wider research community.
As research in multimodal image and text foundation models continues to advance, we can expect to see even more innovative applications emerge, transforming fields like computer vision, natural language processing, and human-computer interaction. The future of AI is undeniably multimodal, and these groundbreaking models are leading the way.